
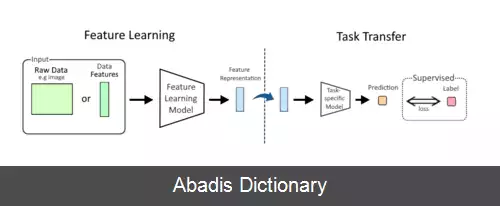
در یادگیری ماشین، یادگیری ویژگی یا یادگیری ارائه [ ۱] مجموعه ای از روش هاست که به یک سیستم اجازه می دهد نمایش های مورد نیاز برای تشخیص یا طبقه بندی ویژگی ها را از داده های خام به طور خودکار کشف کند. این روش جایگزین مهندسی ویژگی های دستی می شود و به یک ماشین اجازه می دهد تا هم ویژگی ها را یاد بگیرد و هم برای انجام یک کار خاص از آن ها استفاده کند.
یادگیری ویژگی از این واقعیت نشات می گیرد که وظایف یادگیری ماشین مانند طبقه بندی اغلب به ورودی هایی نیاز دارند که از نظر ریاضی و محاسباتی برای پردازش مناسب هستند. در حالی که برای داده های دنیای واقعی مانند تصاویر، ویدئوها و داده های حسگرها ( سنسورها ) نمی توان ویژگی های مشخص را به صورت الگوریتمی تعیین کرد. حالت دیگر کشف این ویژگی ها یا ارائه ها از طریق بررسی، بدون استفاده از الگوریتم های صریح است.
یادگیری ویژگی می تواند با ناظر ( تحت نظارت ) یا بدون ناظر باشد.
• در یادگیری ویژگی تحت نظارت ، ویژگی ها با استفاده از داده های ورودی دارای برچسب یاد می گیرند. به عنوان مثال می توان به شبکه های عصبی تحت نظارت، پرسپترون چند لایه و یادگیری فرهنگ لغت ( تحت نظارت ) اشاره کرد.
• در یادگیری ویژگی بدون ناظر ، ویژگی ها با داده های ورودی بدون برچسب یاد می گیرند. به عنوان مثال می توان به یادگیری فرهنگ لغت، تجزیه و تحلیل مولفه های مستقل، رمزگذارهای خودکار، فاکتوراسیون ماتریسی و اشکال مختلف خوشه بندی اشاره کرد.
یادگیری ویژگی با نظارت ، یادگیری ویژگیهای داده های دارای برچسب است. برچسب داده به سیستم اجازه می دهد تا خطا را محاسبه کند و اگر سیستم قادر به تولید برچسب نبود، می تواند به عنوان بازخورد برای اصلاح روند یادگیری ( کاهش / به حداقل رساندن خطا ) استفاده شود.
یادگیری فرهنگ لغت مجموعه ای ( واژه نامه ) از عناصر نماینده را از داده های ورودی ایجاد می کند، به طوری که هر نقطه داده می تواند به عنوان یک جمع وزنی از عناصر نماینده نشان داده شود. عناصر فرهنگ لغت و وزن ها را می توان با به حداقل رساندن میانگین خطای نمایش ( بیش از داده های ورودی ) ، همراه با تنظیم L 1 روی وزن ها برای ایجاد پراکندگی ( به عنوان مثال، نمایش هر نقطه داده فقط چند وزن غیر صفر دارد ) .
یادگیری دیکشنری تحت نظارت هم از ساختار زمینه داده های ورودی و هم از برچسب ها برای بهینه سازی عناصر فرهنگ استفاده می کند. به عنوان مثال ، یک روش یادگیری فرهنگ لغت تحت نظارت با بهینه سازی مشترک عناصر فرهنگ لغت ، وزن برای نمایش نقاط داده و پارامترهای طبقه بندی بر اساس داده های ورودی ، یادگیری فرهنگ لغت را بر روی مشکلات طبقه بندی اعمال کرد. به طور خاص ، یک مسئله به صورت مسئله کمینه سازی فرموله می شود ، جایی که تابع هدف شامل خطای طبقه بندی، خطای نمایش، تنظیم L1 در وزن های نمایانگر برای هر نقطه داده ( برای فعال کردن نمایش پراکنده داده ها ) و تنظیم L2 در پارامترها از طبقه بندی کننده است.
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفیادگیری ویژگی از این واقعیت نشات می گیرد که وظایف یادگیری ماشین مانند طبقه بندی اغلب به ورودی هایی نیاز دارند که از نظر ریاضی و محاسباتی برای پردازش مناسب هستند. در حالی که برای داده های دنیای واقعی مانند تصاویر، ویدئوها و داده های حسگرها ( سنسورها ) نمی توان ویژگی های مشخص را به صورت الگوریتمی تعیین کرد. حالت دیگر کشف این ویژگی ها یا ارائه ها از طریق بررسی، بدون استفاده از الگوریتم های صریح است.
یادگیری ویژگی می تواند با ناظر ( تحت نظارت ) یا بدون ناظر باشد.
• در یادگیری ویژگی تحت نظارت ، ویژگی ها با استفاده از داده های ورودی دارای برچسب یاد می گیرند. به عنوان مثال می توان به شبکه های عصبی تحت نظارت، پرسپترون چند لایه و یادگیری فرهنگ لغت ( تحت نظارت ) اشاره کرد.
• در یادگیری ویژگی بدون ناظر ، ویژگی ها با داده های ورودی بدون برچسب یاد می گیرند. به عنوان مثال می توان به یادگیری فرهنگ لغت، تجزیه و تحلیل مولفه های مستقل، رمزگذارهای خودکار، فاکتوراسیون ماتریسی و اشکال مختلف خوشه بندی اشاره کرد.
یادگیری ویژگی با نظارت ، یادگیری ویژگیهای داده های دارای برچسب است. برچسب داده به سیستم اجازه می دهد تا خطا را محاسبه کند و اگر سیستم قادر به تولید برچسب نبود، می تواند به عنوان بازخورد برای اصلاح روند یادگیری ( کاهش / به حداقل رساندن خطا ) استفاده شود.
یادگیری فرهنگ لغت مجموعه ای ( واژه نامه ) از عناصر نماینده را از داده های ورودی ایجاد می کند، به طوری که هر نقطه داده می تواند به عنوان یک جمع وزنی از عناصر نماینده نشان داده شود. عناصر فرهنگ لغت و وزن ها را می توان با به حداقل رساندن میانگین خطای نمایش ( بیش از داده های ورودی ) ، همراه با تنظیم L 1 روی وزن ها برای ایجاد پراکندگی ( به عنوان مثال، نمایش هر نقطه داده فقط چند وزن غیر صفر دارد ) .
یادگیری دیکشنری تحت نظارت هم از ساختار زمینه داده های ورودی و هم از برچسب ها برای بهینه سازی عناصر فرهنگ استفاده می کند. به عنوان مثال ، یک روش یادگیری فرهنگ لغت تحت نظارت با بهینه سازی مشترک عناصر فرهنگ لغت ، وزن برای نمایش نقاط داده و پارامترهای طبقه بندی بر اساس داده های ورودی ، یادگیری فرهنگ لغت را بر روی مشکلات طبقه بندی اعمال کرد. به طور خاص ، یک مسئله به صورت مسئله کمینه سازی فرموله می شود ، جایی که تابع هدف شامل خطای طبقه بندی، خطای نمایش، تنظیم L1 در وزن های نمایانگر برای هر نقطه داده ( برای فعال کردن نمایش پراکنده داده ها ) و تنظیم L2 در پارامترها از طبقه بندی کننده است.


wiki: یادگیری ویژگی