
تفسیر داده های دارای ابعاد بالا، یعنی داده هایی که نیاز به بیش از ۲ یا ۳ بعد برای نمایش داده شدن دارند، دشوار است. یک راه برای ساده سازی این است که فرض کنیم داده ها روی یک خمینه غیرخطی نهفته در فضای مورد نظر قرار دارند. اگر بعد خمینه به مقدار کافی کم باشد، داده ها را می توان در این فضای با ابعاد پایین تر نشان داد.
بسیاری از الگوریتم های کاهش غیرخطی ابعاد با روش های خطی زیر ارتباط دارند:
• تحلیل مؤلفه های مستقل ( ICA )
• تحلیل مؤلفه های اصلی ( PCA )
• تجزیه مقدارهای منفرد ( SVD )
• آنالیز عامل ها ( Factor Analysis )
روش های غیرخطی را می توان به دو دسته عمده تقسیم کرد:
آن هایی که یک نگاشت ( از فضای با ابعاد بالاتر به خمینهٔ نهفته با ابعاد پایین تر با برعکس ) ( mapping ) هستند، و آن هایی که تنها یک نمایش از داده ها ارائه می کنند. در زمینهٔ یادگیری ماشینی، روش های نگاشت به عنوان مرحلهٔ استخراج ویژگی، پیش از اعمال الگوریتم های شناسایی الگو استفاده می شوند. آن هایی که یک نمایش از داده ها ارائه می کنند، بر اساس داده های مجاورت ـ فاصله بین نقاط ) ـ هستند.
فرض کنید در یک تسک یادگیری ماشین، مجموعه داده را به صورت یک ماتریس D m ∗ n در اختیار دارید به گونه ای که هر کدام از m سطر یک نقطه داده دارای n متغیر ( یا ویژگی یا بعد ) است. در صورتی که تعداد ویژگی ها زیاد باشد، فضای نقطه داده های ممکن به صورت نمایی زیاد می شود که به این پدیده مشقت بعدچندی گفته می شود. به طور مثال اگر هر کدام از متغیرها دارای V مقدار مختلف باشد، V n پیکربندی متفاوت را می توان برای فضای ورودی متصور شد.
یکی از مشکلاتی که این پدیده به همراه دارد یک چالش آماری است. فرض کنید فضای ورودی به صورت یک توری ( grid ) سازماندهی شده است. یک فضا با ابعاد کم را با تعداد کمی نقطه داده می توان توصیف کرد. به طور مثال برای تخمین توزیع احتمال در یک نقطه دلخواه x کافی است تعداد نقطه داده هایی که با نقطه مورد نظر در یک خانه ( مکعب واحد شامل x ) هستند را تقسیم بر تعداد کل نمونه های آموزشی کرد، یا برای تسک طبقه بندی کافی است یک رای گیری حداکثری بین داده های آموزشی در خانه مورد نظر انجام دهیم. اما هرچه ابعاد ورودی بزرگتر می شود، تعداد داده های آموزش مورد نیاز به طور نمایی افزایش می یابد. این چالش آماری الگوریتم های یادگیری ماشین را مستلزم می کند که برای تعمیم به نقطه داده های جدید در فضای ورودی، مجموعه دادگان عظیمی داشته باشند که در عمل دست نیافتنی است. این یکی از انگیزه های پیگیری الگوریتم های یادگیری ژرف است که عموماً بر روی داده های با ابعاد بالا از جمله متن و تصویر بهتر عمل می کنند. [ ۱] یکی دیگر از مشکلات ابعاد بالای ورودی عدم امکان درک شدن توسط انسان ها و مصورسازی داده ها به صورت مستقیم است. این دو مشکل بیان شده انگیزه را برای کاهش غیرخطی ابعاد فراهم می آورد. [ ۲]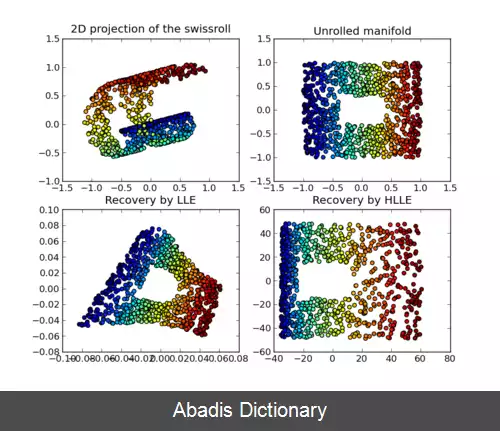


این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفبسیاری از الگوریتم های کاهش غیرخطی ابعاد با روش های خطی زیر ارتباط دارند:
• تحلیل مؤلفه های مستقل ( ICA )
• تحلیل مؤلفه های اصلی ( PCA )
• تجزیه مقدارهای منفرد ( SVD )
• آنالیز عامل ها ( Factor Analysis )
روش های غیرخطی را می توان به دو دسته عمده تقسیم کرد:
آن هایی که یک نگاشت ( از فضای با ابعاد بالاتر به خمینهٔ نهفته با ابعاد پایین تر با برعکس ) ( mapping ) هستند، و آن هایی که تنها یک نمایش از داده ها ارائه می کنند. در زمینهٔ یادگیری ماشینی، روش های نگاشت به عنوان مرحلهٔ استخراج ویژگی، پیش از اعمال الگوریتم های شناسایی الگو استفاده می شوند. آن هایی که یک نمایش از داده ها ارائه می کنند، بر اساس داده های مجاورت ـ فاصله بین نقاط ) ـ هستند.
فرض کنید در یک تسک یادگیری ماشین، مجموعه داده را به صورت یک ماتریس D m ∗ n در اختیار دارید به گونه ای که هر کدام از m سطر یک نقطه داده دارای n متغیر ( یا ویژگی یا بعد ) است. در صورتی که تعداد ویژگی ها زیاد باشد، فضای نقطه داده های ممکن به صورت نمایی زیاد می شود که به این پدیده مشقت بعدچندی گفته می شود. به طور مثال اگر هر کدام از متغیرها دارای V مقدار مختلف باشد، V n پیکربندی متفاوت را می توان برای فضای ورودی متصور شد.
یکی از مشکلاتی که این پدیده به همراه دارد یک چالش آماری است. فرض کنید فضای ورودی به صورت یک توری ( grid ) سازماندهی شده است. یک فضا با ابعاد کم را با تعداد کمی نقطه داده می توان توصیف کرد. به طور مثال برای تخمین توزیع احتمال در یک نقطه دلخواه x کافی است تعداد نقطه داده هایی که با نقطه مورد نظر در یک خانه ( مکعب واحد شامل x ) هستند را تقسیم بر تعداد کل نمونه های آموزشی کرد، یا برای تسک طبقه بندی کافی است یک رای گیری حداکثری بین داده های آموزشی در خانه مورد نظر انجام دهیم. اما هرچه ابعاد ورودی بزرگتر می شود، تعداد داده های آموزش مورد نیاز به طور نمایی افزایش می یابد. این چالش آماری الگوریتم های یادگیری ماشین را مستلزم می کند که برای تعمیم به نقطه داده های جدید در فضای ورودی، مجموعه دادگان عظیمی داشته باشند که در عمل دست نیافتنی است. این یکی از انگیزه های پیگیری الگوریتم های یادگیری ژرف است که عموماً بر روی داده های با ابعاد بالا از جمله متن و تصویر بهتر عمل می کنند. [ ۱] یکی دیگر از مشکلات ابعاد بالای ورودی عدم امکان درک شدن توسط انسان ها و مصورسازی داده ها به صورت مستقیم است. این دو مشکل بیان شده انگیزه را برای کاهش غیرخطی ابعاد فراهم می آورد. [ ۲]



wiki: کاهش غیرخطی ابعاد