
امروزه سرطان به عنوان یکی از بیماری های خطرناک به شمار می رود که زیرگروه های بسیاری دارد. پیش بینی به موقع و پیشگیری از این بیماری ضروری است و می تواند موجب راحتتر شدن روند درمان شود. همچنین طبقه بندی سرطان ها به پرریسک و کم ریسک امری مهم می باشد. از طرفی دیگر یادگیری ماشین شاخه ای از هوش مصنوعی می باشد که تکنیک های آماری و احتمالی و بهینه سازی را به کار می گیرد تا کامپیوترها از این طریق بتوانند از مثال های گذشته بیاموزند تا الگوهایی از مجموعه داده های پیچیده و بزرگ به دست آورند.
برای یک پیش بینی معقول باید پزشک معالج اطلاعات مهم مانند: اطلاعات مبتنی بر سلول و اطلاعات جمعیت شناختی و اطلاعات بالینی را به دقت جمع آوری کند. سابقهٔ خانوادگی، سن، رژیم، چاقی، عادات پرخطر ( سیگار کشیدن و الکل نوشیدن ) و قرار گرفتن در معرض محیط سرطان زا ( اشعهٔ ماورا بنفش و … ) همگی در پیش بینی سرطان نقش دارند. متأسفانه این موارد برای تشخیص صحیح کافی نیستند و به برخی جزئیات در مورد تومور یا ژنتیک بیمار نیاز است. با توسعهٔ تکنولوژی های ژنومیک و پروتئومیک و تصویربرداری می توان اطلاعات مورد نیاز مولکولی را به دست آورد. برخی جهش ها در برخی ژن ها نیز می توانند ابزار قدرتمندی برای پیش بینی سرطان باشند. ترکیب داده های مولکولی با عوامل مقیاس بزرگی که نام برده شد می تواند باعث افزایش صحت پیش بینی شود. اگرچه هر چقدر که تعداد پارامترهای مؤثر بیشتر شود توانایی ربط دادن آن ها به یکدیگر کم می شود.
تقریباً همهٔ پیش بینی ها دارای ۴ نوع دادهٔ ورودی هستند:
• دادهٔ ژنومیک
• دادهٔ پروتئومیک
• دادهٔ بالینی
• ترکیبی از سه مورد فوق[ ۱]
با استفاده از روش های یادگیری ماشین می توان دقت پیش بینی حساسیت سرطان، عود سرطان و بقای سرطان را بهبود بخشید. امروزه با استفاده از این روش ها دقت پیش بینی سرطان ۱۵٪ تا ۲۰٪ بهبود شده است. [ ۲]
دو دسته ی اصلی در انواع روش های یادگیری ماشین وجود دارد:
• یادگیری با نظارت
• یادگیری بدون نظارت
در یادگیری با نظارت مجموعه ای از داده های مجموعه ی آموزش با برچسب استفاده می شوند به این صورت که داده ی ورودی به خروجی مطلوب نگاشت می شود. برای مثال اگر از الگوریتم های یادگیری ماشین در تشخیص سگ از میان حیوانات دیگر استفاده کنیم باید ابتدا به عنوان مجموعه ی آموزش تصویر های زیادی از انواع و اقسام سگ ها به آن داده شود و سپس به عنوان برچسب گفته شود که این تصاویر سگ هستند. یکی از انواع روش های یادگیری با نظارت طبقه بندی است که داده ها را به مجموعه ای از کلاس های محدود طبقه بندی می کند.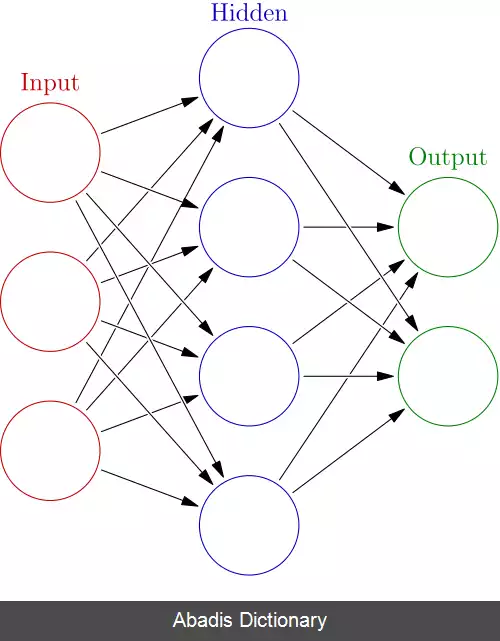
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفبرای یک پیش بینی معقول باید پزشک معالج اطلاعات مهم مانند: اطلاعات مبتنی بر سلول و اطلاعات جمعیت شناختی و اطلاعات بالینی را به دقت جمع آوری کند. سابقهٔ خانوادگی، سن، رژیم، چاقی، عادات پرخطر ( سیگار کشیدن و الکل نوشیدن ) و قرار گرفتن در معرض محیط سرطان زا ( اشعهٔ ماورا بنفش و … ) همگی در پیش بینی سرطان نقش دارند. متأسفانه این موارد برای تشخیص صحیح کافی نیستند و به برخی جزئیات در مورد تومور یا ژنتیک بیمار نیاز است. با توسعهٔ تکنولوژی های ژنومیک و پروتئومیک و تصویربرداری می توان اطلاعات مورد نیاز مولکولی را به دست آورد. برخی جهش ها در برخی ژن ها نیز می توانند ابزار قدرتمندی برای پیش بینی سرطان باشند. ترکیب داده های مولکولی با عوامل مقیاس بزرگی که نام برده شد می تواند باعث افزایش صحت پیش بینی شود. اگرچه هر چقدر که تعداد پارامترهای مؤثر بیشتر شود توانایی ربط دادن آن ها به یکدیگر کم می شود.
تقریباً همهٔ پیش بینی ها دارای ۴ نوع دادهٔ ورودی هستند:
• دادهٔ ژنومیک
• دادهٔ پروتئومیک
• دادهٔ بالینی
• ترکیبی از سه مورد فوق[ ۱]
با استفاده از روش های یادگیری ماشین می توان دقت پیش بینی حساسیت سرطان، عود سرطان و بقای سرطان را بهبود بخشید. امروزه با استفاده از این روش ها دقت پیش بینی سرطان ۱۵٪ تا ۲۰٪ بهبود شده است. [ ۲]
دو دسته ی اصلی در انواع روش های یادگیری ماشین وجود دارد:
• یادگیری با نظارت
• یادگیری بدون نظارت
در یادگیری با نظارت مجموعه ای از داده های مجموعه ی آموزش با برچسب استفاده می شوند به این صورت که داده ی ورودی به خروجی مطلوب نگاشت می شود. برای مثال اگر از الگوریتم های یادگیری ماشین در تشخیص سگ از میان حیوانات دیگر استفاده کنیم باید ابتدا به عنوان مجموعه ی آموزش تصویر های زیادی از انواع و اقسام سگ ها به آن داده شود و سپس به عنوان برچسب گفته شود که این تصاویر سگ هستند. یکی از انواع روش های یادگیری با نظارت طبقه بندی است که داده ها را به مجموعه ای از کلاس های محدود طبقه بندی می کند.



