
در بیوانفورماتیک، هم تراز کردن توالی ( به انگلیسی: Sequence Alignment ) به روش های مرتب کردن توالی های آران ای، دی ان ای و پروتئین گفته می شود به طوری که مکان های مشابهت بین توالی ها را مشخص کند. این مکان های مشابهت بین دو یا چند توالی، می تواند نشانگر ارتباط عملکردی، ساختاری یا تکاملی مابین توالی ها باشد. توالی یک دی ان ای یا آران ای، دنباله ای از نوکلئوتیدهای تشکیل دهندهٔ آن و توالی یک پروتئین، دنباله ای از پس مانده های تقطیر اسیدهای آمینه آن است. توالی های هم تراز شده را معمولاً به شکل سطرهایی زیر هم درون یک ماتریس نشان می دهند. در صورت لزوم در برخی مکان های توالی بین نوکلئوتیدها ( پس مانده ها ) فاصله اضافه می کنند تا در چند ستون پی در پی کاراکترهای یکسان زیر هم قرار بگیرند.
هم تراز کردن توالی ها برای دنباله های غیر زیستی مانند دنباله های موجود در زبان های طبیعی یا داده های مالی نیز استفاده می شود.
اگر دو توالی که هم تراز کردن بر روی آن ها صورت می گیرد دارای یک جد مشترک باشند، پس از هم تراز کردن، مکان هایی که دو دنباله با یکدیگر مطابقت ندارند را می توان به عنوان جهش نقطه ای تفسیر کرد. همچنین فاصله ها را می توان به عنوان جهش رخنه ای یا جهش حذفی در یکی یا هر دو از اجداد در هنگام انشعاب یافتن از یکدیگر تفسیر کرد. در هم تراز کردن توالی های پروتئینی، درجه شباهت بین اسیدهای آمینه یک ناحیه خاص در توالی را می توان به عنوان مقیاسی برای اینکه یک منطقه چقدر بین اجداد حفظ شده است در نظر گرفت. عدم وجود جانشینی یا وجود تنها تعدادی جانشینی بسیار حفظ شده ( جانشینی اسیدهای آمینه ای که زنجیره های جانبی اشان خواص بیوشمیایی مشابه دارند ) در ناحیه ای خاص از توالی، این ناحیه را به عنوان ناحیه ای مهم از لحاظ ساختاری یا کارکردی پیشنهاد می دهد. هر چند در دی ان ای و آران ای بازهای نوکلئوتیدها نسبت به آمینواسیدها بیشتر به هم شباهت دارند، جفت بازهای حفظ شده نیز می توانند نشان دهندهٔ وظیفهٔ ساختاری یا کارکردی مشابه باشند.
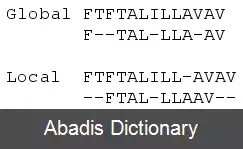
توالی های بسیار کوچک یا بسیار مشابه می توانند به صورت دستی هم تراز شوند. اما، اکثر مسائل جالب توجه نیاز به هم تراز کردن توالی های طولانی، بسیار متغیر یا با تعداد بسیار زیاد دارند که نمی توانند تنها توسط تلاش انسانی هم تراز شوند. در عوض، دانش انسان، در ساختن الگوریتم هایی که هم تراز کردن توالی ها را با کیفیت بالا را انجام می دهند، و گاهی در تنظیم نتایج نهایی برای منعکس ساختن الگوهایی که نمایش آن ها به صورت الگوریتمی سخت است ( مخصوصاً در مورد توالی های نوکلوئوتیدی ) ، به کار می رود. رویکردهای محاسباتی برای هم تراز کردن توالی ها به طور کلی در دو دسته جا می گیرد: هم تراز کردن سراسری و هم تراز کردن محلی. محاسبه هم ترازی سراسری، شکلی از بهینه سازی سراسری است که به هم ترازی فشار می آورد تا در کل طول توالی های مورد جستجو گسترده شود. بلعکس، هم تراز کردن محلی، نواحی مشابه درون توالی های بلند را که معمولاً در طول توالی بسیار متفاوت اند، تشخیص می دهد. معمولاً هم تراز کردن محلی ترجیح داده می شود، اما محاسبه اش می تواند به علت مشکلات تشخیص نواحی مشابه، مشکل تر باشد. الگوریتم های محاسباتی گوناگونی برای مسئله هم تراز کردن توالی ها به کار رفته است، که شامل روش های آهسته ولی بهینه کننده ای مانند برنامه ریزی پویا، و روش های کارآمد اما نه دارای الگوریتم های کاملاً ابتکاری یا روش های احتمالاتی، که برای جستجو در پایگاه داده های در مقیاس بزرگ به کار می رود، می باشد.

این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفهم تراز کردن توالی ها برای دنباله های غیر زیستی مانند دنباله های موجود در زبان های طبیعی یا داده های مالی نیز استفاده می شود.
اگر دو توالی که هم تراز کردن بر روی آن ها صورت می گیرد دارای یک جد مشترک باشند، پس از هم تراز کردن، مکان هایی که دو دنباله با یکدیگر مطابقت ندارند را می توان به عنوان جهش نقطه ای تفسیر کرد. همچنین فاصله ها را می توان به عنوان جهش رخنه ای یا جهش حذفی در یکی یا هر دو از اجداد در هنگام انشعاب یافتن از یکدیگر تفسیر کرد. در هم تراز کردن توالی های پروتئینی، درجه شباهت بین اسیدهای آمینه یک ناحیه خاص در توالی را می توان به عنوان مقیاسی برای اینکه یک منطقه چقدر بین اجداد حفظ شده است در نظر گرفت. عدم وجود جانشینی یا وجود تنها تعدادی جانشینی بسیار حفظ شده ( جانشینی اسیدهای آمینه ای که زنجیره های جانبی اشان خواص بیوشمیایی مشابه دارند ) در ناحیه ای خاص از توالی، این ناحیه را به عنوان ناحیه ای مهم از لحاظ ساختاری یا کارکردی پیشنهاد می دهد. هر چند در دی ان ای و آران ای بازهای نوکلئوتیدها نسبت به آمینواسیدها بیشتر به هم شباهت دارند، جفت بازهای حفظ شده نیز می توانند نشان دهندهٔ وظیفهٔ ساختاری یا کارکردی مشابه باشند.
توالی های بسیار کوچک یا بسیار مشابه می توانند به صورت دستی هم تراز شوند. اما، اکثر مسائل جالب توجه نیاز به هم تراز کردن توالی های طولانی، بسیار متغیر یا با تعداد بسیار زیاد دارند که نمی توانند تنها توسط تلاش انسانی هم تراز شوند. در عوض، دانش انسان، در ساختن الگوریتم هایی که هم تراز کردن توالی ها را با کیفیت بالا را انجام می دهند، و گاهی در تنظیم نتایج نهایی برای منعکس ساختن الگوهایی که نمایش آن ها به صورت الگوریتمی سخت است ( مخصوصاً در مورد توالی های نوکلوئوتیدی ) ، به کار می رود. رویکردهای محاسباتی برای هم تراز کردن توالی ها به طور کلی در دو دسته جا می گیرد: هم تراز کردن سراسری و هم تراز کردن محلی. محاسبه هم ترازی سراسری، شکلی از بهینه سازی سراسری است که به هم ترازی فشار می آورد تا در کل طول توالی های مورد جستجو گسترده شود. بلعکس، هم تراز کردن محلی، نواحی مشابه درون توالی های بلند را که معمولاً در طول توالی بسیار متفاوت اند، تشخیص می دهد. معمولاً هم تراز کردن محلی ترجیح داده می شود، اما محاسبه اش می تواند به علت مشکلات تشخیص نواحی مشابه، مشکل تر باشد. الگوریتم های محاسباتی گوناگونی برای مسئله هم تراز کردن توالی ها به کار رفته است، که شامل روش های آهسته ولی بهینه کننده ای مانند برنامه ریزی پویا، و روش های کارآمد اما نه دارای الگوریتم های کاملاً ابتکاری یا روش های احتمالاتی، که برای جستجو در پایگاه داده های در مقیاس بزرگ به کار می رود، می باشد.



wiki: هم ترازسازی توالی