
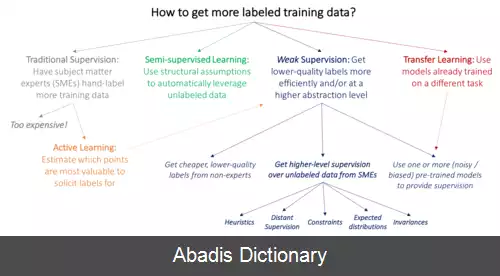
نظارت ضعیف ( به انگلیسی: Weak Supervision ) شاخه ای از یادگیری ماشین است که در آن منابع نویز دار, محدود یا با دقت پایین برای ایجاد سیگنال های نظارتی مربوط به برچسب زدن روی حجم انبوهی از دادهٔ آموزش درون یک محیط یادگیری نظارت شده اعمال می شود. [ ۱] این روش هزینه های احتمالی ای که لیبل زدن به صورت دستی ایجاد می کند مانند زمان بر بودن را از بین می برد. به جای این روش برچسب های ضعیف و درک آن که آن ها ناقصند اما میتوانند یک مدل قوی بسازند به کارگرفته می شوند.
به خصوص در پردازش زبان های طبیعی که در آن ما الگوهای بسیاری خاص برای داده ها داریم که باعث می شود یک مدل از پیش آموزش دیده با الگوهای خاص به خوبی عمل نکند، در این مورد نظارت ضعیف به بهبود عملکرد مدل در مورد الگوها کمک می کند. [ ۲]
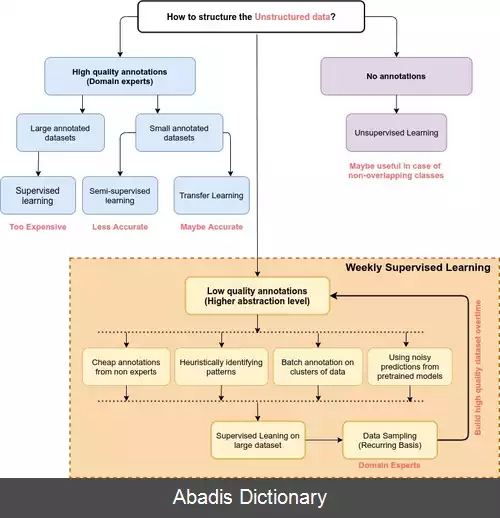
در کل سطوح نشانه گذاری داده ها را می توان به ۳ گروه تقسیم کرد:
در این بخش داده ها با کیفیت خوبی نشانه گذاری شده اند و این نشانه گذاری ها قابل اعتماد هستند.
با توجه به اندازه ٔ مجموعه داده ها در این گروه می توان از رویکردهای مختلف استفاده کرد. مثلا اگر اندازهٔ مجموعه داده بزرگ باشد می توان از رویکرد یادگیری بانظارت و اگر اندازه مجموعه داده کوچک باشد می توان از رویکرد یادگیری انتقالی یا یادگیری نیمه نظارتی استفاده کرد.
در این بخش با تکنیک های مختلف مثل روش های برچسب گذاری ضعیف، روش های اکتشافی الگویابی، برچسب گذاری خوشه ای و استفاده از مدل های از قبل آموزش دیده به عنوان یک پیش بینی کننده نویزدار، کیفیت نشانه گذاری را بالا می بریم و سپس از روش های ذکر شده استفاده می کنیم.
در این بخش می توان از روش های خوشه بندی استفاده کرد.
مدل های یادگیری ماشین و تکنیک های آن به صورت روبه افزایشی قابل دسترسی توسط محققان و توسعه دهندگان است. [ ۳] کاربرد این مدل ها در دنیای واقعی اما, بستگی به دسترسی به دادهٔ آموزش با کیفیت بالا دارد. این نیاز به دادهٔ آموزش برچسبدار یک مانع بزرگی برای کار کردن مدل های یادگیری ماشین در دنیای واقعی مانند داخل یک سازمان یا صنعت است. این گلوگاه در راه های مختلفی خود را بروز می دهد. به طور مثال:
هنگامی که تکنیک های یادگیری ماشین در کاربردی جدید شروع به کار میکنند, معمولا دادهٔ آموزش به اندازهٔ کافی برای اعمال فرآیند های مرسوم نیست. [ ۳] هرچند بعضی صنایع این مزیت را دارند که مقدار کافی دادهٔ آموزش آماده دارند. جمع آوری دادهٔ آموزش نیاز به گذشت زمان بسیار زیاد و هزینهٔ بالا شود. بنابراین آنهایی که چنین نیستند ممکن است با مشکل جدی روبه رو شوند.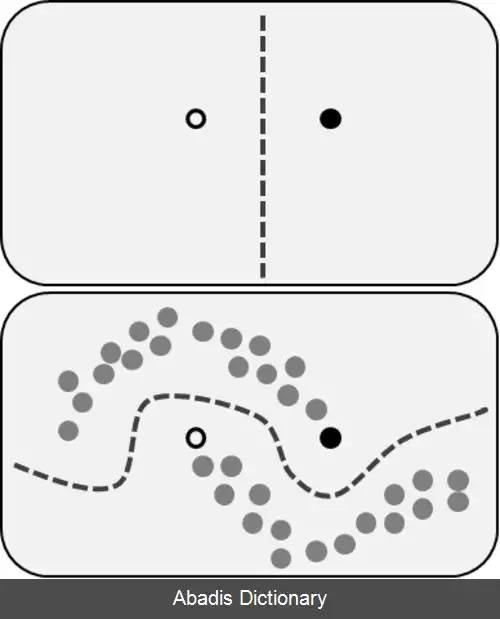
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفبه خصوص در پردازش زبان های طبیعی که در آن ما الگوهای بسیاری خاص برای داده ها داریم که باعث می شود یک مدل از پیش آموزش دیده با الگوهای خاص به خوبی عمل نکند، در این مورد نظارت ضعیف به بهبود عملکرد مدل در مورد الگوها کمک می کند. [ ۲]
در کل سطوح نشانه گذاری داده ها را می توان به ۳ گروه تقسیم کرد:
در این بخش داده ها با کیفیت خوبی نشانه گذاری شده اند و این نشانه گذاری ها قابل اعتماد هستند.
با توجه به اندازه ٔ مجموعه داده ها در این گروه می توان از رویکردهای مختلف استفاده کرد. مثلا اگر اندازهٔ مجموعه داده بزرگ باشد می توان از رویکرد یادگیری بانظارت و اگر اندازه مجموعه داده کوچک باشد می توان از رویکرد یادگیری انتقالی یا یادگیری نیمه نظارتی استفاده کرد.
در این بخش با تکنیک های مختلف مثل روش های برچسب گذاری ضعیف، روش های اکتشافی الگویابی، برچسب گذاری خوشه ای و استفاده از مدل های از قبل آموزش دیده به عنوان یک پیش بینی کننده نویزدار، کیفیت نشانه گذاری را بالا می بریم و سپس از روش های ذکر شده استفاده می کنیم.
در این بخش می توان از روش های خوشه بندی استفاده کرد.
مدل های یادگیری ماشین و تکنیک های آن به صورت روبه افزایشی قابل دسترسی توسط محققان و توسعه دهندگان است. [ ۳] کاربرد این مدل ها در دنیای واقعی اما, بستگی به دسترسی به دادهٔ آموزش با کیفیت بالا دارد. این نیاز به دادهٔ آموزش برچسبدار یک مانع بزرگی برای کار کردن مدل های یادگیری ماشین در دنیای واقعی مانند داخل یک سازمان یا صنعت است. این گلوگاه در راه های مختلفی خود را بروز می دهد. به طور مثال:
هنگامی که تکنیک های یادگیری ماشین در کاربردی جدید شروع به کار میکنند, معمولا دادهٔ آموزش به اندازهٔ کافی برای اعمال فرآیند های مرسوم نیست. [ ۳] هرچند بعضی صنایع این مزیت را دارند که مقدار کافی دادهٔ آموزش آماده دارند. جمع آوری دادهٔ آموزش نیاز به گذشت زمان بسیار زیاد و هزینهٔ بالا شود. بنابراین آنهایی که چنین نیستند ممکن است با مشکل جدی روبه رو شوند.



wiki: نظارت ضعیف