
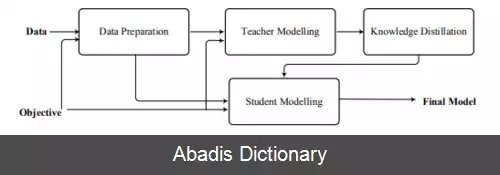
تقطیر دانش ( به انگلیسی: Knowledge distillation ) یکی از روش های مرسوم برای انتقال اطلاعات بین مدل ها است که در چند سال گذشته بسیار مورد بررسی قرار گرفته است. در دنیای یادگیری ماشین، به فرایند انتقال دانش از یک مدل نسبتاً بزرگ به یک مدل کوچک تقطیر دانش گفته می شود. مدل های بزرگ مثل شبکه های عصبی ژرف یا مدل های یادگیری ماشین جمعی ( به انگلیسی: Ensemble Models ) ظرفیت دانش و یادگیری بیشتری در مقایسه با مدل های کوچک تر دارند اما از لحاظ محاسباتی بسیار سنگین تر هستند. تقطیر دانش، این دانش را از مدل های پیچیده به مدل های ساده تر و کوچک تر منتفل می کند و تلاش می کند که این کار را با کمترین میزان هدررفت دانش انجام دهد.
در واقع نیاز به آن، زمانی حس شد که مدل های پیچیده ای داریم که توانایی حل مسائل سخت را دارند و می خواهیم آن ها را در دستگاه های تلفن همراه یا جاهای دیگر که کمبود منابع داریم، به کار بگیریم. به طور معمول در دنیای یادگیری ماشین، ما از مدل های مشابه برای آموزش و استنتاج استفاده می کنیم اما نکتهٔ قابل توجه این است که نیازمندی های این دو قسمت با هم متفاوت است. در یادگیری معمولاً ما دنبال این هستیم که پارامترهای یادگیری را بدست آوریم. برای این کار می توان زمان بسیار زیادی را صرف کرد و مسیرهای مختلف زیادی را امتحان کرد. همچنین می توان از تکنیک های مختلفی استفاده کرد؛ مثلاً عمق شبکه را بیشتر کنیم یا از داده های بیشتری کمک بگیریم یا برای تنظیم مدل ( به انگلیسی: Regularization ) از حذف تصادفی ( به انگلیسی: Dropout ) استفاده کنیم. اما در استنتاج بسیار واضح است که به این کارها و امتحان کردن ها نیاز نداریم. در مرحله استنتاج مهم ترین نیازها دقت بالای مدل و زمان مصرفی برای پیش بینی کردن است. اگر مدل شما بسیار کند باشد یا منابع محاسباتی زیادی نیاز داشته باشد، دیگر دقت بالای آن اهمیت چندانی پیدا نمی کند. در این جا است که ایدهٔ اساسی تقطیر دانش شکل می گیرد.
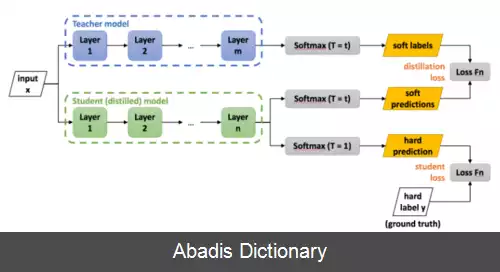
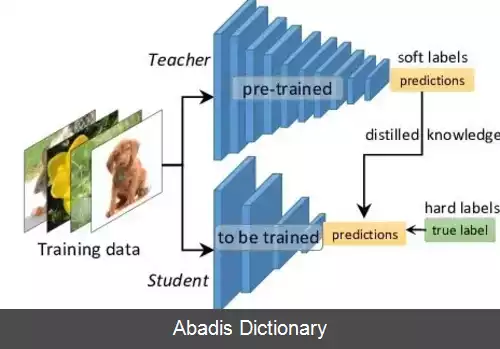
این روش، فرایندی برای آموزش یک مدل ساده است، به طوری که دانش مدل پیچیده را تا حد امکان به آن انتقال دهیم. معمولاً مدل پیچیده را معلم ( به انگلیسی: Teacher Model ) و مدل ساده را دانش آموز ( به انگلیسی: Student Model ) می نامیم. مدل معلم به طور معمول مدلی است که پارامترهای بسیار زیادی دارد یا یک مجموعه از چندین مدل است و نمی توان از آن ها به راحتی در جاهای مختلف که توانایی محاسباتی بسیار زیادی نداریم، استفاده کرد. مدل دانش آموز نیز معمولاً مدلی ساده و بسیار سریع است. [ ۲]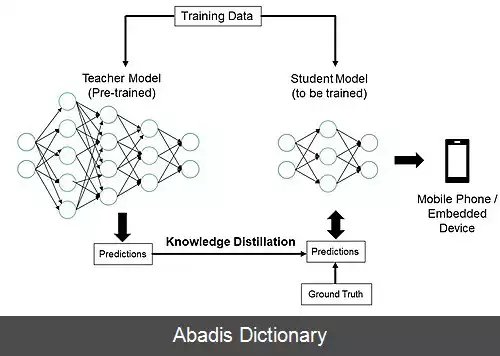
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفدر واقع نیاز به آن، زمانی حس شد که مدل های پیچیده ای داریم که توانایی حل مسائل سخت را دارند و می خواهیم آن ها را در دستگاه های تلفن همراه یا جاهای دیگر که کمبود منابع داریم، به کار بگیریم. به طور معمول در دنیای یادگیری ماشین، ما از مدل های مشابه برای آموزش و استنتاج استفاده می کنیم اما نکتهٔ قابل توجه این است که نیازمندی های این دو قسمت با هم متفاوت است. در یادگیری معمولاً ما دنبال این هستیم که پارامترهای یادگیری را بدست آوریم. برای این کار می توان زمان بسیار زیادی را صرف کرد و مسیرهای مختلف زیادی را امتحان کرد. همچنین می توان از تکنیک های مختلفی استفاده کرد؛ مثلاً عمق شبکه را بیشتر کنیم یا از داده های بیشتری کمک بگیریم یا برای تنظیم مدل ( به انگلیسی: Regularization ) از حذف تصادفی ( به انگلیسی: Dropout ) استفاده کنیم. اما در استنتاج بسیار واضح است که به این کارها و امتحان کردن ها نیاز نداریم. در مرحله استنتاج مهم ترین نیازها دقت بالای مدل و زمان مصرفی برای پیش بینی کردن است. اگر مدل شما بسیار کند باشد یا منابع محاسباتی زیادی نیاز داشته باشد، دیگر دقت بالای آن اهمیت چندانی پیدا نمی کند. در این جا است که ایدهٔ اساسی تقطیر دانش شکل می گیرد.
این روش، فرایندی برای آموزش یک مدل ساده است، به طوری که دانش مدل پیچیده را تا حد امکان به آن انتقال دهیم. معمولاً مدل پیچیده را معلم ( به انگلیسی: Teacher Model ) و مدل ساده را دانش آموز ( به انگلیسی: Student Model ) می نامیم. مدل معلم به طور معمول مدلی است که پارامترهای بسیار زیادی دارد یا یک مجموعه از چندین مدل است و نمی توان از آن ها به راحتی در جاهای مختلف که توانایی محاسباتی بسیار زیادی نداریم، استفاده کرد. مدل دانش آموز نیز معمولاً مدلی ساده و بسیار سریع است. [ ۲]




wiki: تقطیر دانش