
تخصیص پنهان دیریکله ( به انگلیسی: Latent Dirichlet Allocation ) یا LDA یک مدل تولیدی در آمار است. این مدل برای مدل سازی تعدادی متغیرهای پنهان ( عناوین ) در مجموعه ای از متن ها که شامل کلمات هستند به وجود آمده است. در حقیقت در یک متن شامل تعدادی کلمه می توان به هر کلمه تعدادی عنوان با احتمال مشخص نسبت داد که در نهایت با ترکیب با هم یک متن و عنوان آن را تشکیل می دهند. [ ۱]
در واقع می توان هر متن را به عنوان یک توزیع مخلوط از عناوین دید. این مشابه آنالیز پنهان مفهومی احتمالی با این تفاوت که در LDA یک توزیع احتمال پیشین از نوع توزیع دریکله در نظر گرفته می شود. اگرچه LDA با توزیع دریکله یکنواخت معادل با آنالیز پنهان مفهومی احتمالی است. [ ۲]
هر عنوان مجموعه ای از کلمات را با احتمال مشخصی ایجاد می کند. کلماتی که تعلق خاصی به برخی از عناوین ندارند ( مانند the در انگلیسی ) می توان آن ها را با احتمال یکنواختی در هرکدام از عناوین قرار داد؛ یا اینکه آن ها را دستهٔ خاصی قرار داد. باید توجه کرد که تعریف صریحی برای عنوان از دیدگاه های معناشناسی یا معرفت شناسی مشخص نمی شود. بلکه اختصاص عناوین با یادگیری با نظارت برخی از کلمات و اختصاص آن ها به عناوین و میزان رخدادهای آن ها انجام می شود.
نکتهٔ دیگر این است که در این مدل چیزی برای مدل سازی ترتیب یا همبستگی عناوین در نظر گرفته نمی شود، و هر متن به عنوان کیسه کلمات در نظرگرفته شده و فرض تعویض پذیری ( تئوری دی فینتی ) انجام می شود.
در شکل مدل LDA نمایش داده شده است. M تعداد متن ها و N تعداد کلمات در هر متن است. پارامترهای مدل عبارتند از:
تنها متغیرهای مشاهده شده بقیه متغیر پنهان پنهان هستند.
اکنون می توان کل داده ها را ایجاد شده از طریق مدل فرض شده بر اساس متغیرهای پنهان در نظر گرفت:
۱. انتخاب توزیع دیریکله θ i ∼ D i r ( α ) به ازای i ∈ { 1 , … , M } .
۲. انتخاب توزیع ϕ k ∼ D i r ( β ) به ازای k ∈ { 1 , … , K } .
۳. به ازای هر کلمه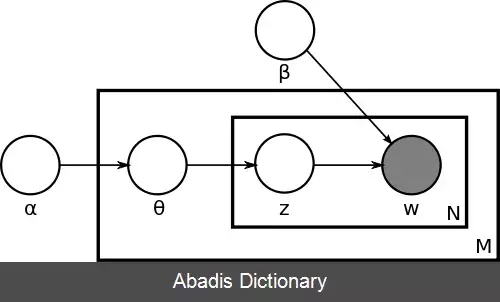
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفدر واقع می توان هر متن را به عنوان یک توزیع مخلوط از عناوین دید. این مشابه آنالیز پنهان مفهومی احتمالی با این تفاوت که در LDA یک توزیع احتمال پیشین از نوع توزیع دریکله در نظر گرفته می شود. اگرچه LDA با توزیع دریکله یکنواخت معادل با آنالیز پنهان مفهومی احتمالی است. [ ۲]
هر عنوان مجموعه ای از کلمات را با احتمال مشخصی ایجاد می کند. کلماتی که تعلق خاصی به برخی از عناوین ندارند ( مانند the در انگلیسی ) می توان آن ها را با احتمال یکنواختی در هرکدام از عناوین قرار داد؛ یا اینکه آن ها را دستهٔ خاصی قرار داد. باید توجه کرد که تعریف صریحی برای عنوان از دیدگاه های معناشناسی یا معرفت شناسی مشخص نمی شود. بلکه اختصاص عناوین با یادگیری با نظارت برخی از کلمات و اختصاص آن ها به عناوین و میزان رخدادهای آن ها انجام می شود.
نکتهٔ دیگر این است که در این مدل چیزی برای مدل سازی ترتیب یا همبستگی عناوین در نظر گرفته نمی شود، و هر متن به عنوان کیسه کلمات در نظرگرفته شده و فرض تعویض پذیری ( تئوری دی فینتی ) انجام می شود.
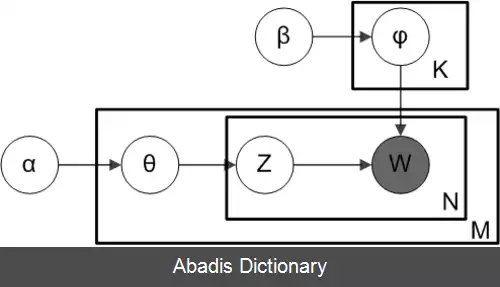
در شکل مدل LDA نمایش داده شده است. M تعداد متن ها و N تعداد کلمات در هر متن است. پارامترهای مدل عبارتند از:
تنها متغیرهای مشاهده شده بقیه متغیر پنهان پنهان هستند.
اکنون می توان کل داده ها را ایجاد شده از طریق مدل فرض شده بر اساس متغیرهای پنهان در نظر گرفت:
۱. انتخاب توزیع دیریکله θ i ∼ D i r ( α ) به ازای i ∈ { 1 , … , M } .
۲. انتخاب توزیع ϕ k ∼ D i r ( β ) به ازای k ∈ { 1 , … , K } .
۳. به ازای هر کلمه


wiki: تخصیص پنهان دیریکله