
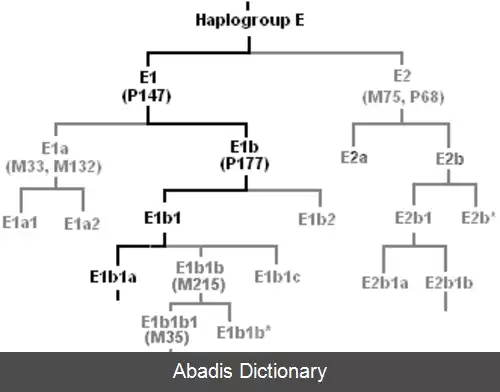
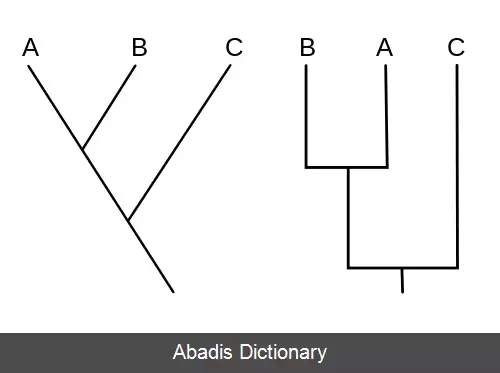
تبارشاخه نما، نمودار تبارشاخه یا نمودار کلادوگرام ( به انگلیسی: Cladogram ) ، یک نمودار شاخه درختی است که رابطهٔ اجدادی میان گونه ها و تکامل درخت زندگی را نمایش می دهد. اگر چه به طور سنتی چنین کلادوگرام هایی بر اساس ویژگی های ریخت شناسی مشخص می شدند اما داده های دنباله دی ان ای، آران ای و فیلوژنتیک محاسباتی به طور رایج تر در تولید کلادوگرام ها نقش دارند.
یک الگوریتم برای تولید یک کلادوگرام این طور هست:
• جمع آوری و سازمان دهی کلادوگرام ها
• فراهم آوردن کلادوگرام های ممکن
• انتخاب بهترین کلادوگرام
یک آنالیز کلادیستیک با داده های زیر آغاز می شود:
• یک فهرست از آرایه ها ( برای نمونه گونه ها ) که سازماندهی شده اند.
• یک فهرست از ویژگی ها برای مقایسه شدن.
• برای هر آرایه مقادیر هر یک از کاراکترهای فهرست شده.
برای نمونه، اگر ۲۰ گونه از پرندگان را آنالیز کنیم، داده های ممکن به صورت زیر می باشد:
• فهرست ۲۰ گونه
• ویژگی هایی همانند دنباله ژنوم، آناتومی اسکلتی، فرآیندهای بیوشیمیایی و رنگ آمیزی پرها می باشد.
• برای هر ۲۰ گونه دنباله ژنوم، آناتومی اسکلتی، فرآیندهای بیوشیمیایی و رنگ آمیزی پر مخصوص به آن.
تمام داده ها سپس در ماتریس ویژگی - آرایه جمع آوری می شوند که اساس انجام آنالیزهای تبارزایی می باشد.
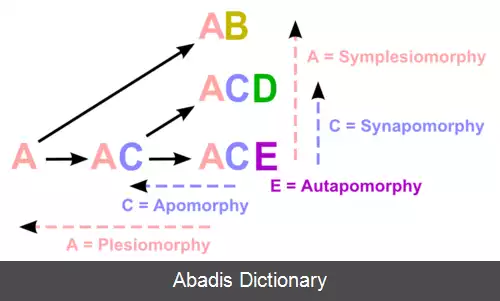
کاراکترهای استفاده شده برای ایجاد یک کلادوگرام می توانند به طور کلی در هر یک از مورفولوژی ها سازمان دهی شوند ( synapsid skull, warm blooded, notochord, unicellular، غیره ) یا مولکولی ( DNA, RNA، یا دیگر اطلاعات ژنتیکی ) . قبل از ظهور دنباله های DNA تمام آنالیزهای کلادوگرام داده های مورفولوژی را استفاده می کردند. همان طور که تعیین توالی دی ان ای ارزان تر و ساده تر گردید، فیلوژنتیک ملکولی روش مشهورتر و مشهورتری برای ایجاد تکامل نژادی شد. [ ۲] با استفاده از معیار پارسیمونی که یکی از چندین روش برای پی بردن به تکامل نژادی از داده های مولکولی می باشد. درست نمایی بیشینه واستنباط بیزی، که مدل های صریحی از تکامل دنباله تأسیس می کنند، روش های non - Hennigian برای ارزیابی داده های دنباله می باشند. روش های قدرتمند دیگر از تکامل نژادی با استفاده از ژنوم retrotransposon marker می باشد که به مسئلهٔ reversion که داده های دنباله را مبتلا می کند کمتر مستعد می باشد. آن ها به صورت معمول فرض می شوند که وقوع کمتری از تشابه ساختمانی دارند زیرا سابقاً تصور می شد که اجتماعشان با ژنوم ها کاملاً تصادفی است. بهر حال لااقل بنظر می رسد در بعضی مواقع این چنین نمی باشد. بصورت مطلوب، مورفولوژی، مولکولی و دیگر فیلوژن های ممکن باید درون یک آنالیز از total evidence ترکیب شوند: تمام آن ها منابع ذاتی متفاوتی از خطاها دارند. برای نمونه همگرایی کاراکتر ( فرگشت همگرا ) در داده های مورفولوژی نسبت به داده های دنباله مولکولی معمول تر است، اما معکوس کاراکتر که غیرقابل فهم هستند در حروف معمول ترند ( ببینید long branch attraction را ) . تشابه ساختمانی مورفولوژیکی می تواند به طور معمول همین طور تشخیص داده شود. اگر وضعیت کاراکترها با جزئیات تعریف شده باشد.
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفیک الگوریتم برای تولید یک کلادوگرام این طور هست:
• جمع آوری و سازمان دهی کلادوگرام ها
• فراهم آوردن کلادوگرام های ممکن
• انتخاب بهترین کلادوگرام
یک آنالیز کلادیستیک با داده های زیر آغاز می شود:
• یک فهرست از آرایه ها ( برای نمونه گونه ها ) که سازماندهی شده اند.
• یک فهرست از ویژگی ها برای مقایسه شدن.
• برای هر آرایه مقادیر هر یک از کاراکترهای فهرست شده.
برای نمونه، اگر ۲۰ گونه از پرندگان را آنالیز کنیم، داده های ممکن به صورت زیر می باشد:
• فهرست ۲۰ گونه
• ویژگی هایی همانند دنباله ژنوم، آناتومی اسکلتی، فرآیندهای بیوشیمیایی و رنگ آمیزی پرها می باشد.
• برای هر ۲۰ گونه دنباله ژنوم، آناتومی اسکلتی، فرآیندهای بیوشیمیایی و رنگ آمیزی پر مخصوص به آن.
تمام داده ها سپس در ماتریس ویژگی - آرایه جمع آوری می شوند که اساس انجام آنالیزهای تبارزایی می باشد.
کاراکترهای استفاده شده برای ایجاد یک کلادوگرام می توانند به طور کلی در هر یک از مورفولوژی ها سازمان دهی شوند ( synapsid skull, warm blooded, notochord, unicellular، غیره ) یا مولکولی ( DNA, RNA، یا دیگر اطلاعات ژنتیکی ) . قبل از ظهور دنباله های DNA تمام آنالیزهای کلادوگرام داده های مورفولوژی را استفاده می کردند. همان طور که تعیین توالی دی ان ای ارزان تر و ساده تر گردید، فیلوژنتیک ملکولی روش مشهورتر و مشهورتری برای ایجاد تکامل نژادی شد. [ ۲] با استفاده از معیار پارسیمونی که یکی از چندین روش برای پی بردن به تکامل نژادی از داده های مولکولی می باشد. درست نمایی بیشینه واستنباط بیزی، که مدل های صریحی از تکامل دنباله تأسیس می کنند، روش های non - Hennigian برای ارزیابی داده های دنباله می باشند. روش های قدرتمند دیگر از تکامل نژادی با استفاده از ژنوم retrotransposon marker می باشد که به مسئلهٔ reversion که داده های دنباله را مبتلا می کند کمتر مستعد می باشد. آن ها به صورت معمول فرض می شوند که وقوع کمتری از تشابه ساختمانی دارند زیرا سابقاً تصور می شد که اجتماعشان با ژنوم ها کاملاً تصادفی است. بهر حال لااقل بنظر می رسد در بعضی مواقع این چنین نمی باشد. بصورت مطلوب، مورفولوژی، مولکولی و دیگر فیلوژن های ممکن باید درون یک آنالیز از total evidence ترکیب شوند: تمام آن ها منابع ذاتی متفاوتی از خطاها دارند. برای نمونه همگرایی کاراکتر ( فرگشت همگرا ) در داده های مورفولوژی نسبت به داده های دنباله مولکولی معمول تر است، اما معکوس کاراکتر که غیرقابل فهم هستند در حروف معمول ترند ( ببینید long branch attraction را ) . تشابه ساختمانی مورفولوژیکی می تواند به طور معمول همین طور تشخیص داده شود. اگر وضعیت کاراکترها با جزئیات تعریف شده باشد.




wiki: تبارشاخه نما