
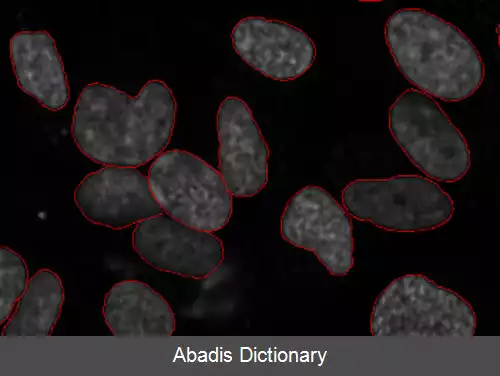
با پیشرفت تکنولوژی و افزایش چشمگیر داده های زیستی، علاوه بر ذخیره سازی و نگهداری، استخراج اطلاعات سودمند از این حجم از داده نیز چالش بزرگی را برای پژوهشگران به وجود آورده است. به این منظور، برای به دست آوردن دانش از داده های زیستی از ابزارها و روش های یادگیری ماشین استفاده می شود. [ ۱] یادگیری ماشین که زیرشاخه ای از علوم رایانه است، دارای کاربردهای بسیاری در بیوانفورماتیک است. بیوانفورماتیک دانشی است که به جنبه های ریاضی و محاسباتی زیست شناسی برای فهم و پردازش داده های زیستی می پردازد. [ ۲]
پیش از ظهور روش های یادگیری ماشین در بیوانفورماتیک، الگوریتم های بیوانفورماتیک به صورت دست نویس و غیرخودکار برنامه نویسی می شدند، که برای مسائلی مانند پیش بینی ساختار پروتئین بسیار دشوار بوده است. روش هایی در یادگیری ماشین مانند یادگیری عمیق به الگوریتم این اجازه را می دهد که از روی ویژگی های اولیهٔ دادهٔ ورودی ویژگی هایی پیچیده تر را برای به کارگیری در الگوریتم یادگیری بسازد. این نوع سیستم ها با داشتن حجم بزرگی از داده برای یادگیری می توانند پیش بینی های کاملاً پیچیده ای را انجام دهند. در سال های اخیر حجم داده های زیستی به شدت افزایش یافته است، که این موضوع استفاده از سیستم های گفته شده را برای پژوهشگران بیوانفورماتیک میسر می کند. [ ۲]
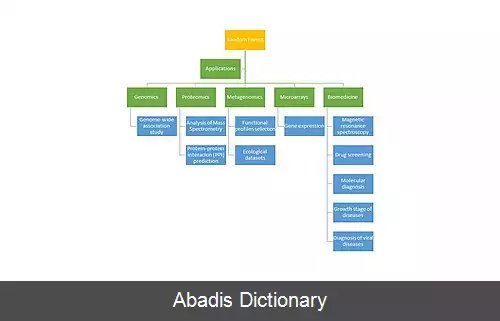
یادگیری ماشین در شش شاخه از زیست شناسی مورد استفاده قرار می گیرد. این شاخه ها عبارتند از: ژنومیک، پروتئومیک، ریزآرایه، زیست شناسی دستگاه ها، تکامل و متن کاوی.
الگوریتم های یادگیری ماشین در بیوانفورماتیک را می توان برای پیش بینی، طبقه بندی و انتخاب ویژگی استفاده کرد. روش های دستیابی به این وظیفه متنوع است و بخش های گسترده ایی را در بر می گیرد. شناخته شده ترین آنها یادگیری ماشین و آمار است. هدف الگوریتم های طبقه بندی و پیش بینی، ساخت مدل هایی است که کلاس ها یا مفاهیم را برای پیش بینی آینده توصیف و متمایز می کنند. تفاوت بین آنها به شرح زیر است:
• الگوریتم های مربوط به طبقه بندی/تشخیص، یک کلاس طبقه بندی را خروجی می دهند، در حالی که الگوریتم های پیش بینی یک ویژگی با ارزش عددی را خروجی می دهد.
• نوع الگوریتم یا فرآیندی که برای ساخت مدل های پیش بینی از داده ها با استفاده از قیاس ها، قوانین، شبکه های عصبی، احتمالات و/یا آمار استفاده می شود.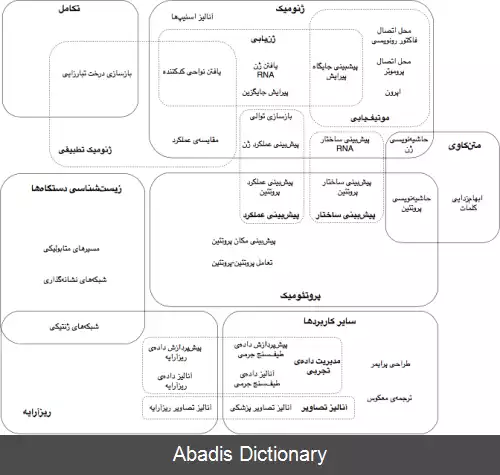
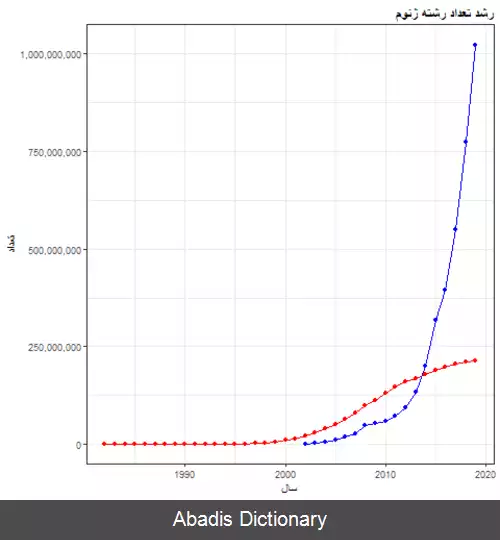

این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفپیش از ظهور روش های یادگیری ماشین در بیوانفورماتیک، الگوریتم های بیوانفورماتیک به صورت دست نویس و غیرخودکار برنامه نویسی می شدند، که برای مسائلی مانند پیش بینی ساختار پروتئین بسیار دشوار بوده است. روش هایی در یادگیری ماشین مانند یادگیری عمیق به الگوریتم این اجازه را می دهد که از روی ویژگی های اولیهٔ دادهٔ ورودی ویژگی هایی پیچیده تر را برای به کارگیری در الگوریتم یادگیری بسازد. این نوع سیستم ها با داشتن حجم بزرگی از داده برای یادگیری می توانند پیش بینی های کاملاً پیچیده ای را انجام دهند. در سال های اخیر حجم داده های زیستی به شدت افزایش یافته است، که این موضوع استفاده از سیستم های گفته شده را برای پژوهشگران بیوانفورماتیک میسر می کند. [ ۲]
یادگیری ماشین در شش شاخه از زیست شناسی مورد استفاده قرار می گیرد. این شاخه ها عبارتند از: ژنومیک، پروتئومیک، ریزآرایه، زیست شناسی دستگاه ها، تکامل و متن کاوی.
الگوریتم های یادگیری ماشین در بیوانفورماتیک را می توان برای پیش بینی، طبقه بندی و انتخاب ویژگی استفاده کرد. روش های دستیابی به این وظیفه متنوع است و بخش های گسترده ایی را در بر می گیرد. شناخته شده ترین آنها یادگیری ماشین و آمار است. هدف الگوریتم های طبقه بندی و پیش بینی، ساخت مدل هایی است که کلاس ها یا مفاهیم را برای پیش بینی آینده توصیف و متمایز می کنند. تفاوت بین آنها به شرح زیر است:
• الگوریتم های مربوط به طبقه بندی/تشخیص، یک کلاس طبقه بندی را خروجی می دهند، در حالی که الگوریتم های پیش بینی یک ویژگی با ارزش عددی را خروجی می دهد.
• نوع الگوریتم یا فرآیندی که برای ساخت مدل های پیش بینی از داده ها با استفاده از قیاس ها، قوانین، شبکه های عصبی، احتمالات و/یا آمار استفاده می شود.





