
یادگیری نیروافزوده یا یادگیری تقویتی یا یادگیری پاداش و تاوان یکی از گرایش های یادگیری ماشینی است که از روانشناسی رفتارگرایی الهام می گیرد. این روش بر رفتارهایی تمرکز دارد که ماشین باید برای بیشینه کردن پاداشش انجام دهد. این مسئله، با توجه به گستردگی اش، در زمینه های گوناگونی بررسی می شود. مانند: نظریه بازی ها، نظریه کنترل، تحقیق در عملیات، نظریه اطلاعات، سامانه چندعامله، هوش ازدحامی، آمار، الگوریتم ژنتیک، بهینه سازی بر مبنای شبیه سازی. در مبحث تحقیق در عملیات و در ادبیات کنترل، حوزه ای که در آن روش یادگیری نیروافزوده مطالعه می شود برنامه نویسی تخمینی پویای ( approximate dynamic programming ) خوانده می شود. این مسئله در تئوری کنترل بهینه نیز مطالعه شده است. البته دغدغه اصلی بیشتر مطالعات در این زمینه، اثبات وجود پاسخ بهینه و یافتن ویژگی های آن است و به دنبال جزئیات یادگیری یا تخمین نیست. یادگیری نیروافزوده در اقتصاد و نظریه بازیها بیشتر به بررسی تعادل های ایجاد شده تحت عقلانیت محدود می پردازد.
در یادگیری ماشینی با توجه به این که بسیاری از الگوریتم های یادگیری نیروافزوده از تکنیک های برنامه نویسی پویا استفاده می کنند معمولاً مسئله تحت عنوان یک فرایند تصمیم گیری مارکف مدل می شود. تفاوت اصلی بین روش های سنتی و الگوریتم های یادگیری نیروافزوده این است که در یادگیری نیروافزوده نیازی به داشتن اطلاعات راجع به فرایند تصمیم گیری ندارد و این که این روش روی فرایندهای مارکف بسیار بزرگی کار می کند که روش های سنتی در آنجا ناکارآمدند.
یادگیری نیروافزوده با یادگیری با نظارت معمول دو تفاوت عمده دارد، نخست اینکه در آن زوج های صحیح ورودی و خروجی در کار نیست و رفتارهای ناکارامد نیز از بیرون اصلاح نمی شوند، و دیگر آنکه تمرکز زیادی روی کارایی زنده وجود دارد که نیازمند پیدا کردن یک تعادل مناسب بین اکتشاف چیزهای جدید و بهره برداری از دانش اندوخته شده دارد. این سبک - سنگین کردن بین بهره برداری و اکتشاف در یادگیری نیروافزوده برای فرایندهای مارکف متناهی، تقریباً به طور کامل در مسئلهٔ راهزن چند دست ( Multi - armed bandit ) بررسی شده.
یادگیری تقویتی را می توان شاخه ای مجزا در یادگیری ماشین در نظر گرفت؛ هرچند شباهت هایی هم با سایر روش های یادگیری ماشین دارد. برای دریافتن این شباهت ها و تفاوت ها بهتر است نگاهی به سایر روش های یادگیری ماشین هم نگاهی داشته باشیم.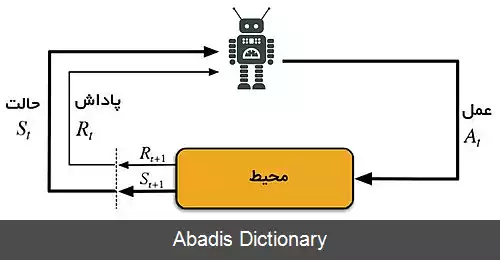


این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفدر یادگیری ماشینی با توجه به این که بسیاری از الگوریتم های یادگیری نیروافزوده از تکنیک های برنامه نویسی پویا استفاده می کنند معمولاً مسئله تحت عنوان یک فرایند تصمیم گیری مارکف مدل می شود. تفاوت اصلی بین روش های سنتی و الگوریتم های یادگیری نیروافزوده این است که در یادگیری نیروافزوده نیازی به داشتن اطلاعات راجع به فرایند تصمیم گیری ندارد و این که این روش روی فرایندهای مارکف بسیار بزرگی کار می کند که روش های سنتی در آنجا ناکارآمدند.
یادگیری نیروافزوده با یادگیری با نظارت معمول دو تفاوت عمده دارد، نخست اینکه در آن زوج های صحیح ورودی و خروجی در کار نیست و رفتارهای ناکارامد نیز از بیرون اصلاح نمی شوند، و دیگر آنکه تمرکز زیادی روی کارایی زنده وجود دارد که نیازمند پیدا کردن یک تعادل مناسب بین اکتشاف چیزهای جدید و بهره برداری از دانش اندوخته شده دارد. این سبک - سنگین کردن بین بهره برداری و اکتشاف در یادگیری نیروافزوده برای فرایندهای مارکف متناهی، تقریباً به طور کامل در مسئلهٔ راهزن چند دست ( Multi - armed bandit ) بررسی شده.
یادگیری تقویتی را می توان شاخه ای مجزا در یادگیری ماشین در نظر گرفت؛ هرچند شباهت هایی هم با سایر روش های یادگیری ماشین دارد. برای دریافتن این شباهت ها و تفاوت ها بهتر است نگاهی به سایر روش های یادگیری ماشین هم نگاهی داشته باشیم.



wiki: یادگیری تقویتی