
کم برازش ( به انگلیسی: Underfitting ) [ ۱] به پدیدهٔ نامطلوبی در آمار گفته می شود که در آن درجه آزادی مدل بسیار کمتر از درجه آزادی واقعی انتخاب شده و در نتیجه اگرچه مدل روی داده استفاده شده برای یادگیری بسیار خوب نتیجه می دهد، اما بر روی داده جدید دارای خطای زیاد است. این مشکل معمولاً زمانی به وقوع می پیوندد که تعداد نمونه هایی که برای آموزش مدل به کار گرفته شده اند کم باشند یا نسبت طول بردارهای ویژگی هر نمونه به تعداد نمونه ها بسیار بالا باشد. این مشکلات را معمولاً با روش های کاهش ابعاد بردارهای ویژگی یا با استفاده از روش های مبتنی بر نگاشت به فضاهایی با ابعاد دیگر مرتفع می نمایند.
کم برازش ( Underfitting ) زمانی اتفاق می افتد که مدل انتخاب شده برای یادگرفتن ساختار و الگوی داده ها بیش از حد ساده باشد. یک مدل کم برازش، مدلی است که در آن برخی از پارامترها که می توانند در یک مدل به درستی ظاهر شوند، وجود ندارند. [ ۲] برای مثال، هنگام برازش یک مدل خطی به داده های غیرخطی، کم برازش اتفاق می افتد. چنین مدلی پیش بینی ضعیفی دارد. برای مثال، هنگام برازش یک مدل خطی به داده های غیرخطی، کم برازش اتفاق می افتد. چنین مدلی پیش بینی ضعیفی دارد. در این مدل خطا روی مجموعه آموزش و تست زیاد است. این مشکلات را می توان با استفاده از مدل های پیچیده تر، مهندسی ویژگی ها و ویژگی های بهتر و کاهش قیود محدودکننده مدل برطرف کرد. محدودکننده مدل برطرف کرد.
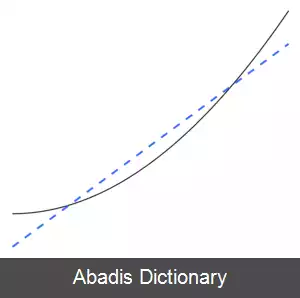
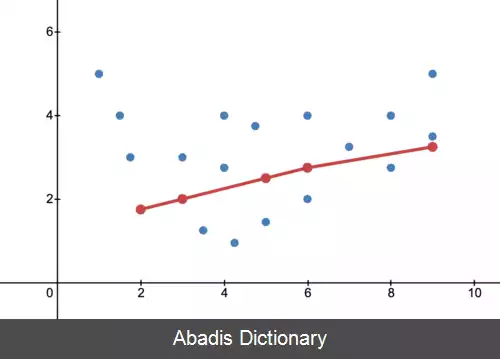
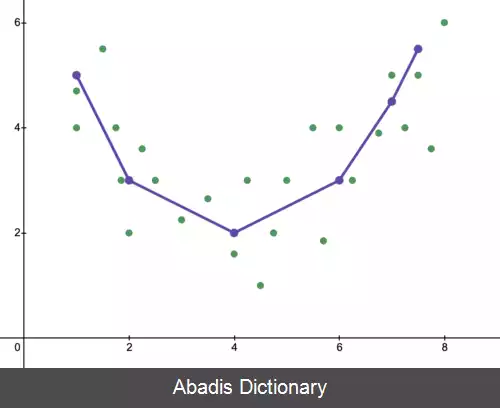
بیش برازش ( Overfitting ) معکوس کم برازش ( Underfitting ) است، به این معنی که مدل آماری یا الگوریتم یادگیری ماشین برای نمایش دقیق داده ها بسیار پیچیده است. نشانه بیش برازش این است که در مدل یا الگوریتم فعلی مورد استفاده، بایاس کم و واریانس زیاد است در صورتی که در کم برازش بایاس زیاد و واریانس کم است. این را می توان از مبادله بایاس - واریانس که روشی برای تجزیه و تحلیل یک مدل یا الگوریتم برای خطای بایاس، خطای واریانس و خطای غیرقابل کاهش است، جمع آوری کرد. با بایاس زیاد و واریانس کم، نتیجه مدل این است که نقاط داده را به طور نادرست نشان می دهد و بنابراین به اندازه کافی قادر به پیش بینی نتایج داده های آینده نیست ( به خطای تعمیم مراجعه کنید ) . در شکل ۲ نشان داده شده است، یک خط نمی تواند برازش خوبی از تمام نقاط داده شده باشد. ما انتظار داریم یک منحنی سهمی شکل را همان طور که در شکل ۳ و شکل ۱ نشان داده شده است ببینیم. همان طور که قبلاً ذکر شد، اگر از شکل ۲ برای آموزش استفاده کنیم ( مدلی خطی را برازش کنیم ) ، و بخواهیم که بر روی شکل ۳ با توجه به آن پیش بینی انجام دهیم، نتایج پیش بینی نادرست بر خلاف نتایج حقیقی بدست می آوریم.
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفکم برازش ( Underfitting ) زمانی اتفاق می افتد که مدل انتخاب شده برای یادگرفتن ساختار و الگوی داده ها بیش از حد ساده باشد. یک مدل کم برازش، مدلی است که در آن برخی از پارامترها که می توانند در یک مدل به درستی ظاهر شوند، وجود ندارند. [ ۲] برای مثال، هنگام برازش یک مدل خطی به داده های غیرخطی، کم برازش اتفاق می افتد. چنین مدلی پیش بینی ضعیفی دارد. برای مثال، هنگام برازش یک مدل خطی به داده های غیرخطی، کم برازش اتفاق می افتد. چنین مدلی پیش بینی ضعیفی دارد. در این مدل خطا روی مجموعه آموزش و تست زیاد است. این مشکلات را می توان با استفاده از مدل های پیچیده تر، مهندسی ویژگی ها و ویژگی های بهتر و کاهش قیود محدودکننده مدل برطرف کرد. محدودکننده مدل برطرف کرد.
بیش برازش ( Overfitting ) معکوس کم برازش ( Underfitting ) است، به این معنی که مدل آماری یا الگوریتم یادگیری ماشین برای نمایش دقیق داده ها بسیار پیچیده است. نشانه بیش برازش این است که در مدل یا الگوریتم فعلی مورد استفاده، بایاس کم و واریانس زیاد است در صورتی که در کم برازش بایاس زیاد و واریانس کم است. این را می توان از مبادله بایاس - واریانس که روشی برای تجزیه و تحلیل یک مدل یا الگوریتم برای خطای بایاس، خطای واریانس و خطای غیرقابل کاهش است، جمع آوری کرد. با بایاس زیاد و واریانس کم، نتیجه مدل این است که نقاط داده را به طور نادرست نشان می دهد و بنابراین به اندازه کافی قادر به پیش بینی نتایج داده های آینده نیست ( به خطای تعمیم مراجعه کنید ) . در شکل ۲ نشان داده شده است، یک خط نمی تواند برازش خوبی از تمام نقاط داده شده باشد. ما انتظار داریم یک منحنی سهمی شکل را همان طور که در شکل ۳ و شکل ۱ نشان داده شده است ببینیم. همان طور که قبلاً ذکر شد، اگر از شکل ۲ برای آموزش استفاده کنیم ( مدلی خطی را برازش کنیم ) ، و بخواهیم که بر روی شکل ۳ با توجه به آن پیش بینی انجام دهیم، نتایج پیش بینی نادرست بر خلاف نتایج حقیقی بدست می آوریم.




wiki: کم برازش