
مدل شیءگرای سند یا دام ( DOM - Document Object Model ) عنوان یکی از دو ساختوارهٔ ( architecture ) اصلی است ( در کنار اس اِی اکس ) که بر اساس آن سندهای اکس ام ال را به اشیایی[ ۲] که در بردارندهٔ آن است، تجزیه نموده، و آن ها را به صورت یک ساختار درختی داده ها در فضای حافظه اصلی پهن می کند. ساختوارهٔ دام، نه به زبان برنامه نویسی خاصّی وابستگی دارد و نه به سکّوی برنامه نویسی ویژه ای، بلکه، به منظور اجراء و پیاده سازی آن باید از یک زبان برنامه نویسی سطح بالا[ ۳] همچون جاوا، سی شارپ، جاوااسکریپت یا مشابه آن ها سود بجوییم. آنسوی رابط کاربر سند با مدلی شیءگرا نمایانده می شود.
سندهای اکس ام ال با دربرداشتن متون زبانی به بیان[ ۴] و نمایش داده های گوناگون اقدام می کنند. ابداع و به کارگیری زبان اکس ام ال را می توان آغاز ماشینی کردن ساختارمند[ ۵] و مقیاس پذیر داده ها هم از جنس رابطه ای و هم از انواع پیچیده تر آن به حساب آورد.
برعکس متون معمولی رایانه ای در مورد متن های اکس ام ال به دلیل در درون داشتن انواع داده ها و دانسته ها در مقیاس ها و در سلسله مراتب مختلف اعمال فنون سنتی پردازش های دنباله ای فایل ها نه عملی ست و نه کارآ. این مشکلات به ویژه در حالات مربوط به افزودن اجزاء و عناصر جدید یا کاستن و برداشتن آن ها به شکل پویش مندانه ( Dynamic ) و در زمان اجراء به اوج می رسد.
در آغاز، گونه های مختلف دام توسط مرورگرهای وب برای دستکاری عناصر سندهای اچ تی ام ال پیاده سازی می شدند. این موضوع، کنسرسیوم وب جهان شمول را وادار کرد که با یک سری مشخصات استاندارد برای دام پیشگام شود ( از این رو آن را W3CDOM نیز می گویند ) .
دام هیچ تنگنایی روی ساختار داده های دربرگیرنده سند قرار نمی دهد. یک سند خوش ساختار می تواند به کمک دام شکل درخت گونه به خودش بگیرد.
بیشتر متن شکن های اکس ام ال ( XML parsers ) ( مانند Xerces ) و پردازندگان اکس اس ال ( مانند Xalan ) پدید آمده اند که از ساختار درختی سود ببرند. چنین پیاده سازی، نیازمند آن است که تمامی محتوای سند شکسته گردیده و در حافظه نگهداری شود. از این رو دام بیشتر برای کارهایی سودمند است که عناصر سند باید به طور تصادفی دستیابی و دستکاری شوند. برای کاربردهای اکس ام ال - محوری که دربرگیرندهٔ دسترسی انتخابی یک خواندن/نوشتن به ازای شکستن است، دام بالاسری قابل ملاحظه ای بر حافظه تحمیل می کند. در این کاربردها، مدل اس اِی اکس ( SAX - Simple API for XML ) از دید سرعت و مصرف حافظه سودمندتر است.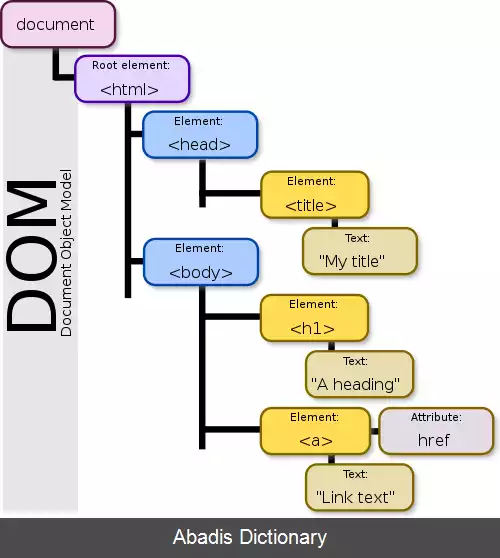
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفسندهای اکس ام ال با دربرداشتن متون زبانی به بیان[ ۴] و نمایش داده های گوناگون اقدام می کنند. ابداع و به کارگیری زبان اکس ام ال را می توان آغاز ماشینی کردن ساختارمند[ ۵] و مقیاس پذیر داده ها هم از جنس رابطه ای و هم از انواع پیچیده تر آن به حساب آورد.
برعکس متون معمولی رایانه ای در مورد متن های اکس ام ال به دلیل در درون داشتن انواع داده ها و دانسته ها در مقیاس ها و در سلسله مراتب مختلف اعمال فنون سنتی پردازش های دنباله ای فایل ها نه عملی ست و نه کارآ. این مشکلات به ویژه در حالات مربوط به افزودن اجزاء و عناصر جدید یا کاستن و برداشتن آن ها به شکل پویش مندانه ( Dynamic ) و در زمان اجراء به اوج می رسد.
در آغاز، گونه های مختلف دام توسط مرورگرهای وب برای دستکاری عناصر سندهای اچ تی ام ال پیاده سازی می شدند. این موضوع، کنسرسیوم وب جهان شمول را وادار کرد که با یک سری مشخصات استاندارد برای دام پیشگام شود ( از این رو آن را W3CDOM نیز می گویند ) .
دام هیچ تنگنایی روی ساختار داده های دربرگیرنده سند قرار نمی دهد. یک سند خوش ساختار می تواند به کمک دام شکل درخت گونه به خودش بگیرد.
بیشتر متن شکن های اکس ام ال ( XML parsers ) ( مانند Xerces ) و پردازندگان اکس اس ال ( مانند Xalan ) پدید آمده اند که از ساختار درختی سود ببرند. چنین پیاده سازی، نیازمند آن است که تمامی محتوای سند شکسته گردیده و در حافظه نگهداری شود. از این رو دام بیشتر برای کارهایی سودمند است که عناصر سند باید به طور تصادفی دستیابی و دستکاری شوند. برای کاربردهای اکس ام ال - محوری که دربرگیرندهٔ دسترسی انتخابی یک خواندن/نوشتن به ازای شکستن است، دام بالاسری قابل ملاحظه ای بر حافظه تحمیل می کند. در این کاربردها، مدل اس اِی اکس ( SAX - Simple API for XML ) از دید سرعت و مصرف حافظه سودمندتر است.


wiki: مدل شیءگرای سند