
مدل سلسله مراتبی[ الف] ( یا مدل چند سطحی[ ب] ) یک مدل رگرسیون خطی است که پارامترهای آن بر اساس خوشه یا سطحی که داده به آن تعلق دارد ممکن است تغییر کند. [ ۱]
پارامترهای مدل سلسله مراتبی که یک مدل رگرسیون خطی است، ممکن است بر اساس خوشه یا سطحی که داده به آن تعلق دارد تغییر کند. به عنوان مثال در مسئله پیش بینی میزان سلامتی فرد از طریق مقدار درآمد او، از آنجا که افرادی که در یک محله زندگی می کنند میزان درآمد و سلامتی آنها به هم وابستگی بیشتری نسبت به بقیه افراد دارد، بهتر است هر محله مدل رگرسیونِ جداگانه خود را داشته باشند. [ ۱] در این مثال یک مدل رگرسیون خطی در سطح اول ( سطح فرد در محله ) ساخته می شود که بعضی یا همه پارامترهای آن می تواند برای هر محله متفاوت باشد. پارامترهای متفاوت می تواند خود از یک مدل رگرسیون دیگر در سطح دوم ( سطح محله ها ) یا به صورت تصادفی تخمین زده شوند. [ ۲]
اگر محله j ، n j داده ( فرد ) داشته باشد، آنگاه برای این محله باید دو پارامتر β 0 j و β 1 j را پیدا کرد. برای داده i ( 1 ≤ i ≤ n j ) رابطه میان میزان درآمد فرد ( X i j ) و میزان سلامتی او ( Y i j ) را به صورت پایین نشان می دهیم؛ در اینجا e i j مقدار خطای تصادفی است که معمولاً از یک توزیع طبیعی پیروی می کند:
Y i j = β 0 j + β 1 j X i j + e i j
حال می توان یا β 0 j یا β 1 j یا هر دو را برای هر محله متفاوت در نظر گرفت. این تفاوت می تواند تصادفی مدل سازی شود یا خود از یک مدل رگرسیون خطی دیگر که دارای یک یا چند متغیر مستقل در سطح دو ( سطح محله ) است برآورد شود. اگر فرض کنیم هر دوی β 0 j و β 1 j از یک مدل رگرسیون دیگر می آیند آنگاه می توان به صورت پایین آنها را تخمین زد؛ در این دو معادله W j یک متغیر مستقل در سطح دو ( سطح محله ) است که به عنوان نمونه می تواند میزان ثروت محله باشد و u 0 j و u 1 j خطاهای تصادفی است. [ ۲]
β 0 j = γ 00 + γ 01 W j + u 0 j
β 1 j = γ 10 + γ 11 W j + u 1 j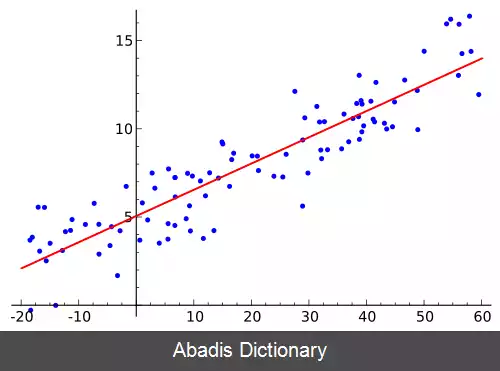
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفپارامترهای مدل سلسله مراتبی که یک مدل رگرسیون خطی است، ممکن است بر اساس خوشه یا سطحی که داده به آن تعلق دارد تغییر کند. به عنوان مثال در مسئله پیش بینی میزان سلامتی فرد از طریق مقدار درآمد او، از آنجا که افرادی که در یک محله زندگی می کنند میزان درآمد و سلامتی آنها به هم وابستگی بیشتری نسبت به بقیه افراد دارد، بهتر است هر محله مدل رگرسیونِ جداگانه خود را داشته باشند. [ ۱] در این مثال یک مدل رگرسیون خطی در سطح اول ( سطح فرد در محله ) ساخته می شود که بعضی یا همه پارامترهای آن می تواند برای هر محله متفاوت باشد. پارامترهای متفاوت می تواند خود از یک مدل رگرسیون دیگر در سطح دوم ( سطح محله ها ) یا به صورت تصادفی تخمین زده شوند. [ ۲]
اگر محله j ، n j داده ( فرد ) داشته باشد، آنگاه برای این محله باید دو پارامتر β 0 j و β 1 j را پیدا کرد. برای داده i ( 1 ≤ i ≤ n j ) رابطه میان میزان درآمد فرد ( X i j ) و میزان سلامتی او ( Y i j ) را به صورت پایین نشان می دهیم؛ در اینجا e i j مقدار خطای تصادفی است که معمولاً از یک توزیع طبیعی پیروی می کند:
Y i j = β 0 j + β 1 j X i j + e i j
حال می توان یا β 0 j یا β 1 j یا هر دو را برای هر محله متفاوت در نظر گرفت. این تفاوت می تواند تصادفی مدل سازی شود یا خود از یک مدل رگرسیون خطی دیگر که دارای یک یا چند متغیر مستقل در سطح دو ( سطح محله ) است برآورد شود. اگر فرض کنیم هر دوی β 0 j و β 1 j از یک مدل رگرسیون دیگر می آیند آنگاه می توان به صورت پایین آنها را تخمین زد؛ در این دو معادله W j یک متغیر مستقل در سطح دو ( سطح محله ) است که به عنوان نمونه می تواند میزان ثروت محله باشد و u 0 j و u 1 j خطاهای تصادفی است. [ ۲]
β 0 j = γ 00 + γ 01 W j + u 0 j
β 1 j = γ 10 + γ 11 W j + u 1 j

wiki: مدل سلسله مراتبی