
در علم یادگیری ماشین و مباحث آماری، دو مفهوم بایاس ( اریبی ) و واریانس حائز اهمیت است. درنتیجه مفهومی به نام مبادله بایاس و واریانس ( Bias - variance tradeoff ) به وجود می آید که بیانگر رابطه بین واریانس و بایاس با یکدیگر در مدل های یادگیری ماشین است. بایاس نتیجهٔ خطا در انتخاب مدل است. در حالی که واریانس نتیجهٔ حساس بودن بیش از اندازه مدل به داده های آموزش است. هریک از این دو، به نوعی مقدار خطای مدل آموزش داده شده را نشان می دهند. آنچه در هنگام آموزش یک مدل دنبال می شود، کم کردن هردوی بایاس و واریانس است. اما در واقعیت با کم کردن واریانس ( که معادل با پیچیده تر کردن مدل است ) بایاس افزایش می یابد. همچنین با کاهش بایاس ( که معادل با ساده تر کردن مدل است ) واریانس افزایش می یابد. درواقع یک موازنه و مبادله بین مقادیر بایاس و واریانس وجود دارد و کاهش هردوی آن ها امکان پذیر نیست. به این حالت تناقض بایاس - واریانس ( Bias - Variance dilemma ) گفته می شود.
بایاس یا همان اریبی، درواقع مقدار اختلاف تابع آموخته شده از تابع حقیقی را نشان می دهد. معمولاً زیاد بودن بایاس منجر به کم برازش ( underfitting ) می شود و در نتیجه مدل حتی در داده های آموزش نیز خروجی مورد انتظار را ندارد. برای مثال اگر تابع حقیقی f ( x ) باشد و روی داده آموزشی S مدل را آموزش بدهیم، مقدار بایاس برابر با عبارت زیر خواهد بود. [ ۱]
B i a s ( h S ) = E S − f ( x )
واریانس به معنی میزان نوسانات مدل حول میانگین آن است. رابطه آن به صورت زیر است. [ ۲]
V a r ( h S ) = E ) 2 ]
درواقع مدلی که بر روی داده به طور کلی آموزش می بیند و روی هر داده به صورت بسیار دقیق تمرکز نمی کند، واریانس کمتری خواهد داشت. هرچه واریانس مدل بیشتر باشد، احتمال بیش برازش ( Overfitting ) بیشتر خواهد بود. در تصویر زیر ارتباط بین بایاس و واریانس، و نقش آن ها در ایجاد بیش برازش یا کم برازش به طور شفاف مشخص شده است.
در یادگیری بانظارت کم برازش هنگامی رخ می دهد که مدل در پیدا کردن الگوی دادهٔ ورودی ناموفق است. این مدل ها عموما واریانس کم و بایاس زیاد دارند. البته نکته قابل توجه آن است که اگر مدلی دارای بایاس زیادی باشد، لزوما واریانس کمی ندارد و ممکن است واریانس مدل نیز زیاد باشد. برای مثال اگر سعی کنیم داده ای که به صورت خطی قابل تفکیک نیست را با استفاده از رگرسیون خطی تفکیک کنیم، این مشکل به وجود می آید، زیرا مدل های رگرسیون خطی قادر به پیدا کردن الگوهای پیچیده در داده نیستند.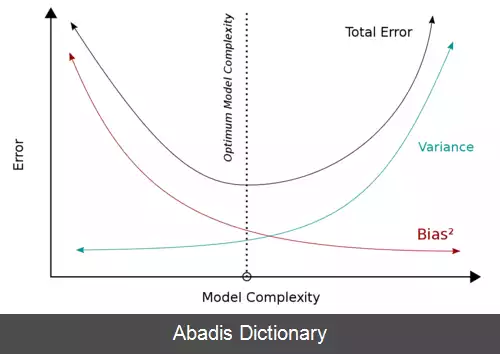
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفبایاس یا همان اریبی، درواقع مقدار اختلاف تابع آموخته شده از تابع حقیقی را نشان می دهد. معمولاً زیاد بودن بایاس منجر به کم برازش ( underfitting ) می شود و در نتیجه مدل حتی در داده های آموزش نیز خروجی مورد انتظار را ندارد. برای مثال اگر تابع حقیقی f ( x ) باشد و روی داده آموزشی S مدل را آموزش بدهیم، مقدار بایاس برابر با عبارت زیر خواهد بود. [ ۱]
B i a s ( h S ) = E S − f ( x )
واریانس به معنی میزان نوسانات مدل حول میانگین آن است. رابطه آن به صورت زیر است. [ ۲]
V a r ( h S ) = E ) 2 ]
درواقع مدلی که بر روی داده به طور کلی آموزش می بیند و روی هر داده به صورت بسیار دقیق تمرکز نمی کند، واریانس کمتری خواهد داشت. هرچه واریانس مدل بیشتر باشد، احتمال بیش برازش ( Overfitting ) بیشتر خواهد بود. در تصویر زیر ارتباط بین بایاس و واریانس، و نقش آن ها در ایجاد بیش برازش یا کم برازش به طور شفاف مشخص شده است.
در یادگیری بانظارت کم برازش هنگامی رخ می دهد که مدل در پیدا کردن الگوی دادهٔ ورودی ناموفق است. این مدل ها عموما واریانس کم و بایاس زیاد دارند. البته نکته قابل توجه آن است که اگر مدلی دارای بایاس زیادی باشد، لزوما واریانس کمی ندارد و ممکن است واریانس مدل نیز زیاد باشد. برای مثال اگر سعی کنیم داده ای که به صورت خطی قابل تفکیک نیست را با استفاده از رگرسیون خطی تفکیک کنیم، این مشکل به وجود می آید، زیرا مدل های رگرسیون خطی قادر به پیدا کردن الگوهای پیچیده در داده نیستند.

wiki: مبادله بایاس و واریانس