
فهرست پرشی داده ساختاری ( ساختمان داده یا Date Structure ) احتمالاتی مبنی بر لیست پیوندی موازی است که در سال 1989 توسط William Pugh ابداع شد . این داده ساختار می تواند مانند درخت دودویی جستجو، عملیات جستجو، درج و حذف را به طور میانگین در O ( log n ) انجام دهد . در واقع فهرست پرشی یک فهرست پیوندی است که هر گره ( node ) آن می تواند چند گره بعد از خودش اشاره کند که تعداد آن به صورت تصادفی مشخص می شود ( هر گره در یک فهرست پیوندی از دو بخش تشکیل شده است؛ یک قسمت برای نگهداری اطلاعات و قسمت دیگر مختص اشاره گرهایی به گره های بعدی ویا قبلی ویا هردو است . ) ← به تعداد گره هایی که هر گره می تواند اشاره کند سایز گره می گوییم.
در لیست های پیوندی معمولی هزینه جستجو، درج و حذف O ( n ) است زیرا برای پیدا کردن گره دادهٔ مربوط، گره ها به ترتیب باید پیمایش شوند در این صورت اگر ما بتوانیم از روی بعضی گره ها بپریم می توانیم هزینه جستجو را پایین بیاوریم مثلاً به داده ساختار زیر دقت کنید :
در این شبه فهرست پرشی سایز هر دو گره متوالی 2، سایز هر چهار گره متوالی 3 و سایز هر گره متوالی i + 1 است همچنین سایز گرهٔ آغازین از همه بیشتر است . شیوه جستجو در این شبه فهرست پرشی مانند جستجوی دودویی است یعنی برای پیدا کردن داده مورد نظر ، هر بار با پایین آمدن تعداد اعداد نصف می شوند ( ابتدا از بالاترین مرحله شروع می کنیم مثلاً اگر فهرست ما 32 گره داشته باشد، ابتدا از گره شانزدهم شروع می کنیم و هر بار با جلو رفتن یا پایین آمدن، تعداد اعداد نصف می شوند ) ؛ واضح است که هزینه جستجو در این داده ساختار از مرتبه O ( log n ) است دقیقاً شبیه جستجوی دودویی.
Comparable & find ( const Comparable & X ) { node=header node; for ( reference level of node from ( nodesize - 1 ) down to 0 ) while ( the node referred to is less than X ) node = node referred to ; if ( node referred to has value X ) return node value; else return item_not_found; } اما اگر ما بخواهیم داده ای را درج یا حذف کنیم چون این فهرست داده های مرتبی دارد، مجبور کل داده ها را یکبار شیفت دهیم پس هزینه درج یا حذف داده از مرتبه O ( n ) است. که برای پایین آوردن زمان درج و حذف، سایز همهٔ گره هایمان را با توزیع یکنواخت احتمالاتی تعیین می کنیم در این صورت چون سایز گره ها به صورت تصادفی مشخص می شود، برای حذف و درج دیگر نیازی به جابجا کردن بقیه داده ها نداریم و فقط کافیست مکان داده مورد نظر را پیدا کنیم که آنهم از مرتبه O ( log n ) است :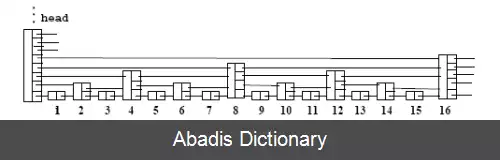
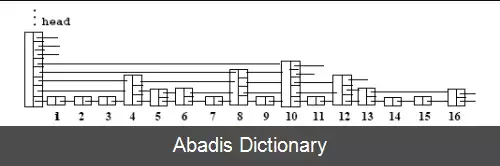
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفدر لیست های پیوندی معمولی هزینه جستجو، درج و حذف O ( n ) است زیرا برای پیدا کردن گره دادهٔ مربوط، گره ها به ترتیب باید پیمایش شوند در این صورت اگر ما بتوانیم از روی بعضی گره ها بپریم می توانیم هزینه جستجو را پایین بیاوریم مثلاً به داده ساختار زیر دقت کنید :
در این شبه فهرست پرشی سایز هر دو گره متوالی 2، سایز هر چهار گره متوالی 3 و سایز هر گره متوالی i + 1 است همچنین سایز گرهٔ آغازین از همه بیشتر است . شیوه جستجو در این شبه فهرست پرشی مانند جستجوی دودویی است یعنی برای پیدا کردن داده مورد نظر ، هر بار با پایین آمدن تعداد اعداد نصف می شوند ( ابتدا از بالاترین مرحله شروع می کنیم مثلاً اگر فهرست ما 32 گره داشته باشد، ابتدا از گره شانزدهم شروع می کنیم و هر بار با جلو رفتن یا پایین آمدن، تعداد اعداد نصف می شوند ) ؛ واضح است که هزینه جستجو در این داده ساختار از مرتبه O ( log n ) است دقیقاً شبیه جستجوی دودویی.
Comparable & find ( const Comparable & X ) { node=header node; for ( reference level of node from ( nodesize - 1 ) down to 0 ) while ( the node referred to is less than X ) node = node referred to ; if ( node referred to has value X ) return node value; else return item_not_found; } اما اگر ما بخواهیم داده ای را درج یا حذف کنیم چون این فهرست داده های مرتبی دارد، مجبور کل داده ها را یکبار شیفت دهیم پس هزینه درج یا حذف داده از مرتبه O ( n ) است. که برای پایین آوردن زمان درج و حذف، سایز همهٔ گره هایمان را با توزیع یکنواخت احتمالاتی تعیین می کنیم در این صورت چون سایز گره ها به صورت تصادفی مشخص می شود، برای حذف و درج دیگر نیازی به جابجا کردن بقیه داده ها نداریم و فقط کافیست مکان داده مورد نظر را پیدا کنیم که آنهم از مرتبه O ( log n ) است :


wiki: فهرست پرشی