
طبقه بندی دودویی ( باینری ) ( به انگلیسی: Binary classification ) در یادگیری ماشین، یک الگوریتم یادگیری نظارت شده است که به مشاهدات جدید را در یکی از دو گروه ممکن دسته بندی می کند. معمولاً این دو گروه را با اعداد 0 و 1 برای دو گروه نمایش می دهند.
در جدول زیر به مثال هایی از کاربرد طبقه بندی دودویی در زمینه های مختلف اشاره شده است.
در طبقه بندی دودویی این دو گروه مختلف اغلب نامتقارن هستند. به عبارت دیگر ممکن است بخش بزرگی از نمونه های موجود که قصد طبقه بندی آن ها را داریم متعلق به یک گروه باشتد و نمونه های مربوط به گروه دیگر از تعداد کمتری برخوردار باشند. بعلاوه در چنین مسائلی عموماً به جای دقت کلی، کمینه کردن خطاهای دیگری برای هر یک از گروه ها مورد علاقه است.
به عنوان مثال در آزمایش پزشکی مربوط به تشخیص سرطان هدف طبقه بندی دو گروه از نمونه های سرطانی و غیرسرطانی است. در حالی که معمولاً تعداد نمونه های سرطانی موجود در یک مجموعه داده در مقایسه با تعداد نمونه های غیرسرطانی بسیار کمتر است. اگر نمونه های سرطانی به عنوان گروه 1 و نمونه های غیرسرطانی به عنوان گروه 0 در نظر گرفته شوند، بدیهی است آن چه از اهمیت بیشتری در این مسئله برخوردار است تشخیص درست نمونه های سرطانی در گروه مربوط به خودش ( گروه 1 ) است، یعنی همان گروهی که نمونه های آن از تعداد کمتری در مجموعه داده برخوردار بود.
طبقه بندی آماری یک مسئله در حوزه یادگیری ماشین است و از روش های یادگیری نظارت شده محسوب می شود. در این روش، دسته بندی ها پیش تعریف شده اند و از آن برای دسته بندی مشاهدات جدید به گروه های تعریف شده استفاده می شود.
زمانی که تنها دو گروه مختلف وجود دارد، این مسئله به عنوان طبقه بندی دودویی آماری شناخته می شود.
برخی از روش های معمول برای طبقه بندی دودویی عبارتند از:
• درخت تصمیم
• جنگل تصادفی
• شبکه های بیزی
• ماشین های بردار پشتیبان
• شبکه های عصبی
• رگرسیون لجستیک
هر یک از روشهای طبقه بندی در دامنه ای خاص عملکرد بهتری دارد که بر اساس تعداد مشاهدات، بعد فضای ویژگی ها و عوامل دیگر مرتبط با مسئله ی موجود تعیین می گردد. به عنوان مثال، جنگل های تصادفی نسبت به ماشین های بردار پشتیبان در طبقه بندی ابر نقاط سه بعدی عملکرد بهتری دارند.
اگر در مثال پیشبینی نتیجه ی تشخیص سرطان، یک مدل طبقه بندی کننده ی دودویی نمونه های سرطانی را به درستی به عنوان "بیمار" شناسایی کند، این حالت به عنوان مثبت صادق[ الف] شناخته می شود. همچنین، اگر مدل، نمونه غیرسرطانی را به عنوان "سالم" تشخیص دهد، این حالت به عنوان منفی صادق[ ب] شناخته می شود. با این حال، ممکن است مدل گروه مربوط به برخی از نمونه ها را به طور نادرست تشخیص دهد. در صورتی که یک نمونه ی سرطانی به عنوان سالم تشخیص داده شود، این خطا به عنوان منفی کاذب[ پ] شناخته می شود. به طور مشابه، اگر نمونه ی غیرسرطانی به عنوان سرطانی تشخیص داده شود، این خطا به عنوان مثبت کاذب[ ت] شناخته می شود.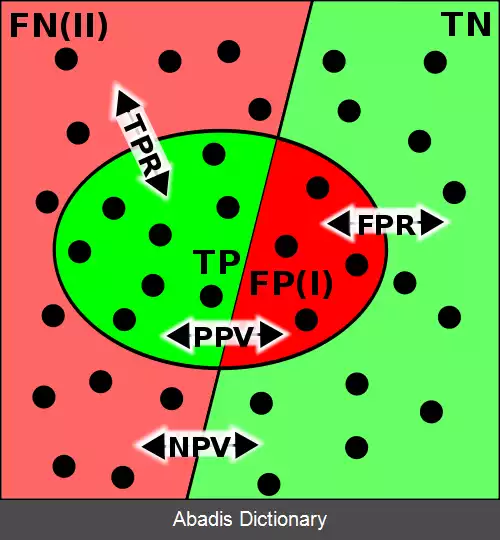
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفدر جدول زیر به مثال هایی از کاربرد طبقه بندی دودویی در زمینه های مختلف اشاره شده است.
در طبقه بندی دودویی این دو گروه مختلف اغلب نامتقارن هستند. به عبارت دیگر ممکن است بخش بزرگی از نمونه های موجود که قصد طبقه بندی آن ها را داریم متعلق به یک گروه باشتد و نمونه های مربوط به گروه دیگر از تعداد کمتری برخوردار باشند. بعلاوه در چنین مسائلی عموماً به جای دقت کلی، کمینه کردن خطاهای دیگری برای هر یک از گروه ها مورد علاقه است.
به عنوان مثال در آزمایش پزشکی مربوط به تشخیص سرطان هدف طبقه بندی دو گروه از نمونه های سرطانی و غیرسرطانی است. در حالی که معمولاً تعداد نمونه های سرطانی موجود در یک مجموعه داده در مقایسه با تعداد نمونه های غیرسرطانی بسیار کمتر است. اگر نمونه های سرطانی به عنوان گروه 1 و نمونه های غیرسرطانی به عنوان گروه 0 در نظر گرفته شوند، بدیهی است آن چه از اهمیت بیشتری در این مسئله برخوردار است تشخیص درست نمونه های سرطانی در گروه مربوط به خودش ( گروه 1 ) است، یعنی همان گروهی که نمونه های آن از تعداد کمتری در مجموعه داده برخوردار بود.
طبقه بندی آماری یک مسئله در حوزه یادگیری ماشین است و از روش های یادگیری نظارت شده محسوب می شود. در این روش، دسته بندی ها پیش تعریف شده اند و از آن برای دسته بندی مشاهدات جدید به گروه های تعریف شده استفاده می شود.
زمانی که تنها دو گروه مختلف وجود دارد، این مسئله به عنوان طبقه بندی دودویی آماری شناخته می شود.
برخی از روش های معمول برای طبقه بندی دودویی عبارتند از:
• درخت تصمیم
• جنگل تصادفی
• شبکه های بیزی
• ماشین های بردار پشتیبان
• شبکه های عصبی
• رگرسیون لجستیک
هر یک از روشهای طبقه بندی در دامنه ای خاص عملکرد بهتری دارد که بر اساس تعداد مشاهدات، بعد فضای ویژگی ها و عوامل دیگر مرتبط با مسئله ی موجود تعیین می گردد. به عنوان مثال، جنگل های تصادفی نسبت به ماشین های بردار پشتیبان در طبقه بندی ابر نقاط سه بعدی عملکرد بهتری دارند.
اگر در مثال پیشبینی نتیجه ی تشخیص سرطان، یک مدل طبقه بندی کننده ی دودویی نمونه های سرطانی را به درستی به عنوان "بیمار" شناسایی کند، این حالت به عنوان مثبت صادق[ الف] شناخته می شود. همچنین، اگر مدل، نمونه غیرسرطانی را به عنوان "سالم" تشخیص دهد، این حالت به عنوان منفی صادق[ ب] شناخته می شود. با این حال، ممکن است مدل گروه مربوط به برخی از نمونه ها را به طور نادرست تشخیص دهد. در صورتی که یک نمونه ی سرطانی به عنوان سالم تشخیص داده شود، این خطا به عنوان منفی کاذب[ پ] شناخته می شود. به طور مشابه، اگر نمونه ی غیرسرطانی به عنوان سرطانی تشخیص داده شود، این خطا به عنوان مثبت کاذب[ ت] شناخته می شود.

wiki: طبقه بندی دودویی