
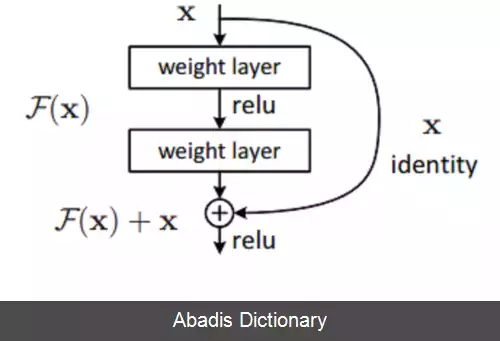
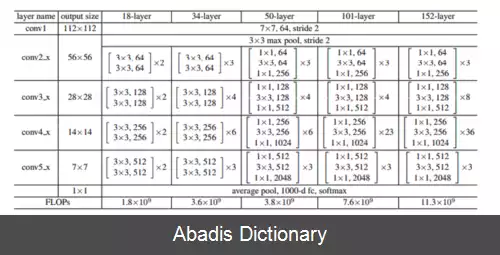
شبکه عصبی پس مانده ( ResNet ) [ ۲] یک نوع شبکه عصبی مصنوعی می باشد. این شبکه در واقع یک نوع دروازه باز یا بدون دروازه شبکه بزرگراه, [ ۳] که اولین شبکه بسیار عمیق پیشخور با هزاران لایه و بسیار عمیق تر از شبکه های قبلی است. در این نوع از شبکه عصبی معمولا از لایه های پرشی و میانبر بین لایه ها استفاده می شود که در پیاده سازی، هر لایه پرشی معمولا از دو یا سه لایه به همراه توابع غیرخطی مانند یکسوساز و نرمال کننده دسته ای استفاده می شود. مدل هایی که دارای چندین لایه پرشی موازی هستند، شبکه های متراکم[ ۴] نام دارند. در زمینه شبکه های عصبی باقی مانده، معمولا شبکه هایی که لایه پرشی ندارند، شبکه ساده توصیف می شوند.
همانند حالت شبکه های عصبی بازگشتی با حافظه طولانی کوتاه - مدت[ ۵] ، دو دلیل اصلی برای اضافه کردن لایه های پرشی وجود دارد: برای جلوگیری از مشکل ناپدید شدن گرادیان ها[ ۶] ، بنابراین منجر به بهینه سازی شبکه های عصبی آسان تر می شود، جایی که مکانیسم های دروازه ای جریان اطلاعات را در بسیاری از لایه ها تسهیل می کنند ( "بزرگراه های اطلاعات" ) [ ۷] [ ۸] ، یا برای کاهش مشکل تخریب ( اشباع دقت ) . که در آن افزودن لایه های بیشتر به یک مدل عمیق مناسب منجر به خطای آموزشی بالاتر می شود. در طول تمرین ( training ) شبکه، وزن ها برای خنثی کردن لایه بالادستی و تقویت لایه ای که قبلاً حذف شده بود، سازگار می شوند. در ساده ترین حالت، فقط وزن های اتصال لایه مجاور تطبیق داده می شوند، بدون وزن صریح برای لایه بالادست. زمانی که یک لایه غیرخطی منفرد از آن عبور می کند، یا زمانی که لایه های میانی همگی خطی هستند، بهترین کار را انجام می دهد. اگر نه، پس باید یک ماتریس وزن صریح برای اتصال پرشی آموخته شود ( یک شبکه بزرگراه باید استفاده شود ) .
پرش به طور مؤثر شبکه را ساده می کند و از لایه های کمتری در مراحل اولیه آموزش استفاده می کند. این امر با کاهش تأثیر گرادیان های در حال از بین رفتن سرعت یادگیری را افزایش می دهد، زیرا لایه های کمتری برای انتشار وجود دارد. سپس شبکه با یادگیری فضای ویژگی، به تدریج لایه های پرش شده را بازیابی می کند. در پایان آموزش، وقتی همه لایه ها گسترش می یابند، به منیفولد نزدیک تر می ماند و بنابراین سریع تر یاد می گیرد. یک شبکه عصبی بدون قطعات باقیمانده بیشتر فضای ویژگی را بررسی می کند. این باعث آسیب پذیری بیشتر آن در برابر اختلالاتی می شود که باعث خروج آن از منیفولد می شود و نیاز به داده های آموزشی اضافی برای بازیابی دارد.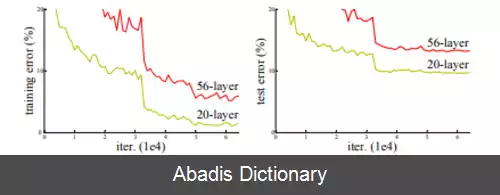
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفهمانند حالت شبکه های عصبی بازگشتی با حافظه طولانی کوتاه - مدت[ ۵] ، دو دلیل اصلی برای اضافه کردن لایه های پرشی وجود دارد: برای جلوگیری از مشکل ناپدید شدن گرادیان ها[ ۶] ، بنابراین منجر به بهینه سازی شبکه های عصبی آسان تر می شود، جایی که مکانیسم های دروازه ای جریان اطلاعات را در بسیاری از لایه ها تسهیل می کنند ( "بزرگراه های اطلاعات" ) [ ۷] [ ۸] ، یا برای کاهش مشکل تخریب ( اشباع دقت ) . که در آن افزودن لایه های بیشتر به یک مدل عمیق مناسب منجر به خطای آموزشی بالاتر می شود. در طول تمرین ( training ) شبکه، وزن ها برای خنثی کردن لایه بالادستی و تقویت لایه ای که قبلاً حذف شده بود، سازگار می شوند. در ساده ترین حالت، فقط وزن های اتصال لایه مجاور تطبیق داده می شوند، بدون وزن صریح برای لایه بالادست. زمانی که یک لایه غیرخطی منفرد از آن عبور می کند، یا زمانی که لایه های میانی همگی خطی هستند، بهترین کار را انجام می دهد. اگر نه، پس باید یک ماتریس وزن صریح برای اتصال پرشی آموخته شود ( یک شبکه بزرگراه باید استفاده شود ) .
پرش به طور مؤثر شبکه را ساده می کند و از لایه های کمتری در مراحل اولیه آموزش استفاده می کند. این امر با کاهش تأثیر گرادیان های در حال از بین رفتن سرعت یادگیری را افزایش می دهد، زیرا لایه های کمتری برای انتشار وجود دارد. سپس شبکه با یادگیری فضای ویژگی، به تدریج لایه های پرش شده را بازیابی می کند. در پایان آموزش، وقتی همه لایه ها گسترش می یابند، به منیفولد نزدیک تر می ماند و بنابراین سریع تر یاد می گیرد. یک شبکه عصبی بدون قطعات باقیمانده بیشتر فضای ویژگی را بررسی می کند. این باعث آسیب پذیری بیشتر آن در برابر اختلالاتی می شود که باعث خروج آن از منیفولد می شود و نیاز به داده های آموزشی اضافی برای بازیابی دارد.



wiki: شبکه عصبی باقی مانده