
شبکه عصبی با تأخیر زمانی ( TDNN ) [ ۱] یک معماری شبکه عصبی مصنوعی چندلایه است که هدف آن ۱ ) رده بندی الگوها با جابه جایی - ناوردا ( به انگلیسی: shift - invariance ) و ۲ ) بافت مدل ( به انگلیسی: model context ) در هر لایه از شبکه است.
رده بندی جابه جایی - ناوردا به این معنی است که رده بند ( به انگلیسی: classification ) قبل از رده بندی نیازی به تقسیم بندی صریح ندارد؛ بنابراین، برای رده بندی الگوی زمانی ( به انگلیسی: temporal pattern ) ( مانند گفتار ) ، TDNN از تعیین نقاط شروع و پایان صداها قبل از رده بندی آنها اجتناب می کند.
برای مدل سازی بافتی در یک TDNN، هر واحد عصبی در هر لایه نه تنها از فعالسازی ها/ویژگی ها در لایه زیر، بلکه از یک الگوی خروجی واحد و بافت آن ورودی دریافت می کند. برای سیگنال های زمانی هر واحد به عنوان ورودی الگوهای فعال سازی را در طول زمان از واحدهای زیر دریافت می کند. با استفاده از رده بندی دو - بُعدی ( تصاویر، الگوهای بسامد - زمانی ) ، TDNN را می توان با جابه جایی - ناوردا در فضای مختصات آموزش داد و از تقسیم بندی پَرسون ( دقیق ) ( به انگلیسی: precise ) در فضای مختصات جلوگیری می کند.
TDNN در اواخر دهه ۱۹۸۰ معرفی شد و برای رده بندی واج ها برای تشخیص گفتار خودکار در سیگنال های گفتاری که تعیین خودکار بخش های پَرسون یا محدوده ویژگی ها دشوار یا غیرممکن بود، اعمال شد. از آنجا که TDNN واج ها و ویژگی های آکوستیک/آوایی زیرین آنها را تشخیص می دهد، مستقل از موقعیت در زمان، کارایی را نسبت به رده بندی ایستایی بهبود می بخشد. [ ۱] [ ۲] همچنین برای سیگنال های دو - بُعدی ( الگوهای بسامد - زمان در گفتار، [ ۳] و الگوی فضای مختصات در OCR[ ۴] ) استفاده شد.
در سال ۱۹۹۰، یاماگوچی و همکاران. مفهوم حداکثر جمع آوری را معرفی کرد. آنها این کار را با ترکیب TDNNها با حداکثر جمع آوری به منظور تحقق بخشیدن به یک سیستم تشخیص کلمه مجزاشده مستقل از گوینده انجام دادند. [ ۵]
• تشخیص گفتار
• واژگان بزرگ تشخیص گفتار
• مستقل از گوینده
• بازآوایش
• گفتار دیداری - شنیداری لب - خوانی
• تشخیص دست خط
• تجزیه و تحلیل ویدئو
• تشخیص تصویر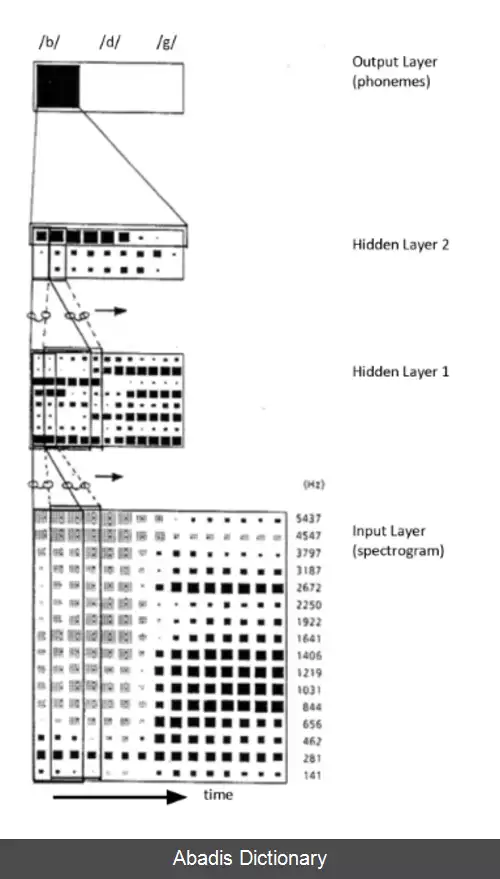
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفرده بندی جابه جایی - ناوردا به این معنی است که رده بند ( به انگلیسی: classification ) قبل از رده بندی نیازی به تقسیم بندی صریح ندارد؛ بنابراین، برای رده بندی الگوی زمانی ( به انگلیسی: temporal pattern ) ( مانند گفتار ) ، TDNN از تعیین نقاط شروع و پایان صداها قبل از رده بندی آنها اجتناب می کند.
برای مدل سازی بافتی در یک TDNN، هر واحد عصبی در هر لایه نه تنها از فعالسازی ها/ویژگی ها در لایه زیر، بلکه از یک الگوی خروجی واحد و بافت آن ورودی دریافت می کند. برای سیگنال های زمانی هر واحد به عنوان ورودی الگوهای فعال سازی را در طول زمان از واحدهای زیر دریافت می کند. با استفاده از رده بندی دو - بُعدی ( تصاویر، الگوهای بسامد - زمانی ) ، TDNN را می توان با جابه جایی - ناوردا در فضای مختصات آموزش داد و از تقسیم بندی پَرسون ( دقیق ) ( به انگلیسی: precise ) در فضای مختصات جلوگیری می کند.
TDNN در اواخر دهه ۱۹۸۰ معرفی شد و برای رده بندی واج ها برای تشخیص گفتار خودکار در سیگنال های گفتاری که تعیین خودکار بخش های پَرسون یا محدوده ویژگی ها دشوار یا غیرممکن بود، اعمال شد. از آنجا که TDNN واج ها و ویژگی های آکوستیک/آوایی زیرین آنها را تشخیص می دهد، مستقل از موقعیت در زمان، کارایی را نسبت به رده بندی ایستایی بهبود می بخشد. [ ۱] [ ۲] همچنین برای سیگنال های دو - بُعدی ( الگوهای بسامد - زمان در گفتار، [ ۳] و الگوی فضای مختصات در OCR[ ۴] ) استفاده شد.
در سال ۱۹۹۰، یاماگوچی و همکاران. مفهوم حداکثر جمع آوری را معرفی کرد. آنها این کار را با ترکیب TDNNها با حداکثر جمع آوری به منظور تحقق بخشیدن به یک سیستم تشخیص کلمه مجزاشده مستقل از گوینده انجام دادند. [ ۵]
• تشخیص گفتار
• واژگان بزرگ تشخیص گفتار
• مستقل از گوینده
• بازآوایش
• گفتار دیداری - شنیداری لب - خوانی
• تشخیص دست خط
• تجزیه و تحلیل ویدئو
• تشخیص تصویر

wiki: شبکه عصبی با تاخیر زمانی