
سلاخی داده یا صید داده یا پی - هکینگ ( به انگلیسی: p - hacking ) [ ۱] سوء استفاده از تحلیل داده برای پیدا کردن الگوهایی در داده است که می توانند تحت عنوان به لحاظ آماری معنادار معرفی شوند در حالی که در واقع هیچ اثر زیربنایی ای وجود ندارد. این کار با انجام آزمون های آماری متعدد روی داده و تنها گزارش آنهایی که نتایج قابل ملاحظه یا معنادار ( significant ) برمی گردانند، صورت می گیرد. به جای آن که یک تک فرضیه درباره اثری زیربنایی قبل از تحلیل وضع شود و آنگاه تک آزمونی برای آن به انجام رسانده شود. [ ۲]
در سلاخی داده با جستجوی جامع ( جستجوی بروت - فورس ) - احتمالاً برای پیدا کردن ترکیبی از متغیرها که همبستگی نشان دهند یا مشاهداتی که در میانگین یا فروپاشیشان توسط متغیری دیگر تفاوت دارند - چندین فرضیه روی یک مجموعه داده تست می شود.
آزمون های معمول برای معناداری آماری بر این اساسند که چقدر احتمال دارد یک نتیجه کاملاً بر حسب تصادف بروز پیدا کند، و همواره مقداری ریسک برای نتایج اشتباه ( مانند رد کردن اشتباهی فرضیه تهی ) را می پذیرند. سطح این ریسک معناداری ( significance ) نام دارد. وقتی تعداد زیادی تست انجام می شود، برخی از آن ها نتایج کاذبی از این نوع تولید می کنند، بنابراین در سطح معناداری ۵ درصد، ۵ درصد از فرضیه های انتخاب شده ی تصادفی ممکن است اشتباهی معنادار اعلام شده باشند، و به همین ترتیب به بقیه ی سطوح. هنگامی که فرضیه های کافی ای آزموده شود، کمابیش مسلم است که برخی به لحاظ آماری معنادار خواهند بود ( گرچه گمراه کننده ) ، چراکه تقریباً هر مجموعه داده ای با هر درجه ای از تصادفی بودن ممکن است شامل همبستگی جعلی باشد. اگر محققانی که از داده کاوی استفاده می کنند محتاط نباشند می توانند به آسانی با این نتایج به بیراهه بروند.
سلاخی داده یکی از مثال های اهمیت ندادن به مسئله ی مقایسه چندگانه است. یک شکل آن زمانی رخ می دهد که بدون اظلاع دادن به خواننده درباره تعداد کل مقایسه زیرگروه ها آن ها را مقایسه کنیم. [ ۳]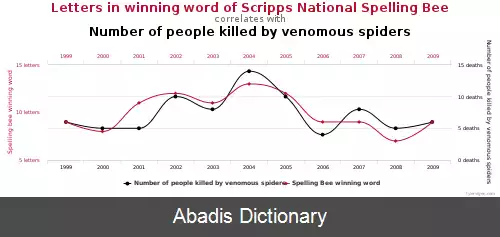
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفدر سلاخی داده با جستجوی جامع ( جستجوی بروت - فورس ) - احتمالاً برای پیدا کردن ترکیبی از متغیرها که همبستگی نشان دهند یا مشاهداتی که در میانگین یا فروپاشیشان توسط متغیری دیگر تفاوت دارند - چندین فرضیه روی یک مجموعه داده تست می شود.
آزمون های معمول برای معناداری آماری بر این اساسند که چقدر احتمال دارد یک نتیجه کاملاً بر حسب تصادف بروز پیدا کند، و همواره مقداری ریسک برای نتایج اشتباه ( مانند رد کردن اشتباهی فرضیه تهی ) را می پذیرند. سطح این ریسک معناداری ( significance ) نام دارد. وقتی تعداد زیادی تست انجام می شود، برخی از آن ها نتایج کاذبی از این نوع تولید می کنند، بنابراین در سطح معناداری ۵ درصد، ۵ درصد از فرضیه های انتخاب شده ی تصادفی ممکن است اشتباهی معنادار اعلام شده باشند، و به همین ترتیب به بقیه ی سطوح. هنگامی که فرضیه های کافی ای آزموده شود، کمابیش مسلم است که برخی به لحاظ آماری معنادار خواهند بود ( گرچه گمراه کننده ) ، چراکه تقریباً هر مجموعه داده ای با هر درجه ای از تصادفی بودن ممکن است شامل همبستگی جعلی باشد. اگر محققانی که از داده کاوی استفاده می کنند محتاط نباشند می توانند به آسانی با این نتایج به بیراهه بروند.
سلاخی داده یکی از مثال های اهمیت ندادن به مسئله ی مقایسه چندگانه است. یک شکل آن زمانی رخ می دهد که بدون اظلاع دادن به خواننده درباره تعداد کل مقایسه زیرگروه ها آن ها را مقایسه کنیم. [ ۳]

wiki: سلاخی داده