
جنگل اِنزِوا ( به انگلیسی Isolation Forest ) یک روش یادگیری نظارت نشده برای تشخیص داده های پَرت است.
یک جنگل انزوا مجموعه ای از درخت های انزوا ( به انگلیسی Isolation Tree ) است. هر درخت انزوا در واقع یک درخت دودویی می باشد.
به طور خلاصه این الگوریتم فضای دادگان را به کمک خطوطی موازی پایه های متعامد فضا جداسازی می کند و به دادگانی که در قسمت های مختلف این فضا قرار گرفته اند امتیازی برای میزان غیر طبیعی بودن اختصاص می دهد. نحوه ی تخصیص این امتیاز نیز بدین صورت است که دادگانی که به خطوط جداساز کمتری برای قرار گیری در یک خوشه ی جداگانه نیاز دارند امتیاز بیشتری دریافت می کنند.
شکل سمت چپ کاربردی از این الگوریتم را نشان میدهد. در ابن شکل فاصله ی زمانی بین فوران بر حسب زمان هر فوران برای آبفشان مخروطی Old Faithful [ ۱] نشان داده شده است. نواحی قرمز تیره امتیاز ناهنجاری بیشتری را نشان می دهند.
در درخت انزوا داده هایی که زودتر از بقیه جدا شوند نزدیک تر به ریشهٔ درخت می باشند و به این ترتیب احتمال پَرت بودن آن ها بیشتر می شود. میزان پرت بودن یک داده در یک درخت انزوا به صورت کلی برابر است با تعداد یال هایی که باید از ریشهٔ درخت تا گرهٔ برگ ( Leaf Node ) طی شود؛ بنابراین هرچه این مسیر کوتاه تر باشد احتمال پرت بودن داده بیشتر می شود. در نهایت جنگل انزوا برای تشخیص پرت بودن میانگین مسیرهای طی شده در هر درخت انزوا برای هر داده را محاسبه می کند. [ ۲]
در یادگیری ماشین، تشخیص ناهنجاری در داده ها یکی از مسائل مهم است. روش های مختلفی برای تشخیص ناهنجاری وجود دارد، اما بسیاری از این روش ها به دلیل نیاز به داده های برچسب خورده و یا تلاش برای تخمین توزیع داده ها، در مواقعی که داده های برچسب خورده کمی در دسترس هستند، مشکل دارند.
این الگوریتم اولین بار در سال 2008 توسط فی تونی لیو و ژی هوا ژو توسعه داده شد. [ ۳] در سال 2010 یک نسخه ی دیگری از این الگوریتم به نام سای فارست[ ۴] توسعه داده شد تا مسئله ی مربوز به ناهنجاری های خوشه ای و ناهنجاری های موازی با پایه های متعامد فضا را حل کند. این الگوریتم برای تشخیص ناهنجاری در داده های بدون برچسب و با توزیع نامعلوم استفاده می شود.
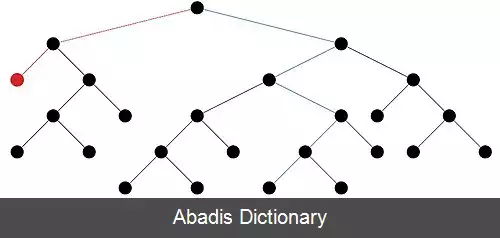
روند ساختن یک درخت ایزوله از روی یک مجموعهٔ دادهٔ X = { x 1 , . . . , x n } به طور خلاصه به ترتیب زیر است:[ ۵]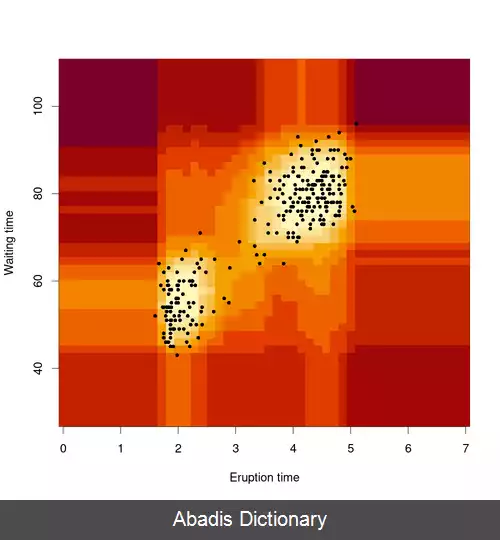

این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفیک جنگل انزوا مجموعه ای از درخت های انزوا ( به انگلیسی Isolation Tree ) است. هر درخت انزوا در واقع یک درخت دودویی می باشد.
به طور خلاصه این الگوریتم فضای دادگان را به کمک خطوطی موازی پایه های متعامد فضا جداسازی می کند و به دادگانی که در قسمت های مختلف این فضا قرار گرفته اند امتیازی برای میزان غیر طبیعی بودن اختصاص می دهد. نحوه ی تخصیص این امتیاز نیز بدین صورت است که دادگانی که به خطوط جداساز کمتری برای قرار گیری در یک خوشه ی جداگانه نیاز دارند امتیاز بیشتری دریافت می کنند.
شکل سمت چپ کاربردی از این الگوریتم را نشان میدهد. در ابن شکل فاصله ی زمانی بین فوران بر حسب زمان هر فوران برای آبفشان مخروطی Old Faithful [ ۱] نشان داده شده است. نواحی قرمز تیره امتیاز ناهنجاری بیشتری را نشان می دهند.
در درخت انزوا داده هایی که زودتر از بقیه جدا شوند نزدیک تر به ریشهٔ درخت می باشند و به این ترتیب احتمال پَرت بودن آن ها بیشتر می شود. میزان پرت بودن یک داده در یک درخت انزوا به صورت کلی برابر است با تعداد یال هایی که باید از ریشهٔ درخت تا گرهٔ برگ ( Leaf Node ) طی شود؛ بنابراین هرچه این مسیر کوتاه تر باشد احتمال پرت بودن داده بیشتر می شود. در نهایت جنگل انزوا برای تشخیص پرت بودن میانگین مسیرهای طی شده در هر درخت انزوا برای هر داده را محاسبه می کند. [ ۲]
در یادگیری ماشین، تشخیص ناهنجاری در داده ها یکی از مسائل مهم است. روش های مختلفی برای تشخیص ناهنجاری وجود دارد، اما بسیاری از این روش ها به دلیل نیاز به داده های برچسب خورده و یا تلاش برای تخمین توزیع داده ها، در مواقعی که داده های برچسب خورده کمی در دسترس هستند، مشکل دارند.
این الگوریتم اولین بار در سال 2008 توسط فی تونی لیو و ژی هوا ژو توسعه داده شد. [ ۳] در سال 2010 یک نسخه ی دیگری از این الگوریتم به نام سای فارست[ ۴] توسعه داده شد تا مسئله ی مربوز به ناهنجاری های خوشه ای و ناهنجاری های موازی با پایه های متعامد فضا را حل کند. این الگوریتم برای تشخیص ناهنجاری در داده های بدون برچسب و با توزیع نامعلوم استفاده می شود.
روند ساختن یک درخت ایزوله از روی یک مجموعهٔ دادهٔ X = { x 1 , . . . , x n } به طور خلاصه به ترتیب زیر است:[ ۵]



wiki: جنگل انزوا