
جدول درهمک سازی یا جدول چکیده سازی[ ۱] یا جدول هش ( به انگلیسی: hash table ) ، در علوم رایانه، نوعی ساختمان داده است که مقدارهایی[ ۲] که باید ذخیره شوند را به وسیله تابع هش ( درهم سازی ) با کلیدهای ویژه ای مرتبط می سازد. عملیات اولیه ای که این جدول تسهیل می کند عمل مراجعه است. به این معنی که کاربر می تواند با سرعتی کارآمد داده مورد نظرش را در آن بیابد. در جدول های هش همچنین افزودن داده های جدید در زمان کم امکان پذیر است. زمان لازم برای جستجو و افزودن وابسته به نوع جدول و میزان داده ها هستند. این زمان می تواند با انتخاب جدول مناسب به مرتبه زمانی O ( 1 ) برسد.
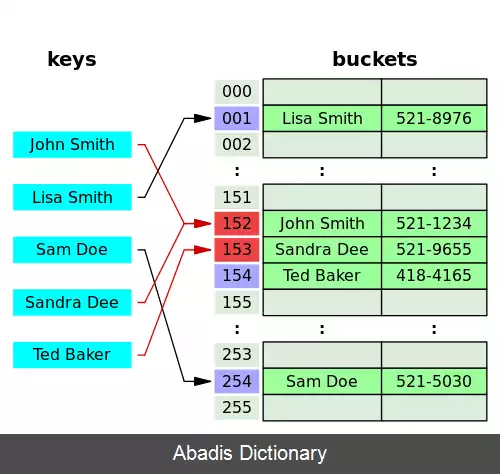
یک تابع هش ایدئال باید هر کلید ممکن را به یک خانه از آرایه متناظر کند، اما این امر در عمل به ندرت اتفاق می افتد. در بیشتر توابع هش فرض بر این است که به طور طبیعی تصادم رخ می دهد، یعنی دو کلید متفاوت، مقدار هش یکسان پیدا می کنند و در نتیجه وارد یک خانه از آرایه می شوند.
در یک جدول با ابعاد خوب، متوسط هزینه ( تعداد دستورالعمل ها ) برای هر جستجو به تعداد عناصر نگهداری شده در آرایه بستگی ندارد. جداول هش بسیاری طراحی شده که مرتبه زمانی حذف و افزودن یک جفت کلید و مقدار اختیاری به طور متوسط ثابت است.
در بسیاری از اوقات، جداول درهم سازی بسیار کارآمدتر از درخت های جستجو یا هر داده ساختار جستجوی دیگری عمل می کند. به همین دلیل، جداول هش به طور گسترده درنرم افزارها، به خصوص در آرایه های شرکت پذیر، ساختار فهرست پایگاه داده، حافظه های نهان و مجموعه ها کاربرد دارند.
جداول هش نباید با هش لیست ها و درخت های هش که در رمزنگاری و انتقال داده استفاده می شود اشتباه گرفته شوند.
در قلب یک جدول درهم سازی، یک آرایهٔ ساده از عناصر وجود دارد؛ که معمولاً به سادگی جدول هش نامیده می شود. جدول هش اندیس یک کلید را محاسبه می کند و از آن اندیس برای جای دادن آن کلید در جدول استفاده می کند.
الگوریتم پایه و اصلی برای جستجو ساده است:
index = f ( key, array_length ) که در آن:
• f: تابع درهم سازی است که اندیس را بر اساس آرایه برمی گرداند
• index: یک اندیس از آرایه است
• key: کلیدی است که قرار است وارد آرایه شود
• array_length: طول آرایه است
فرض کنیم می خواهیم ساختمان داده ای بسازیم و در آن نام ده هزار نفر را ذخیره کنیم. راه حل خام و ساده برای این مسئله آن است که آرایه ای از رشته ها به طول ده هزار بسازیم و نام ها را در آن بریزیم. حال فرض کنیم نامی به ما داده شده است و ما می خواهیم بدانیم این نام در میان داده های ما وجود دارد یا خیر. برای این کار مجبوریم همه داده های درون آرایه از یک تا ده هزار را بپیماییم تا ببینیم نام مورد نظر وجود دارد یا نه. در حقیقت عملیات جستجو در ساختمان داده ما دارای مرتبه زمانی n خواهد بود. ( n تعداد داده ها است )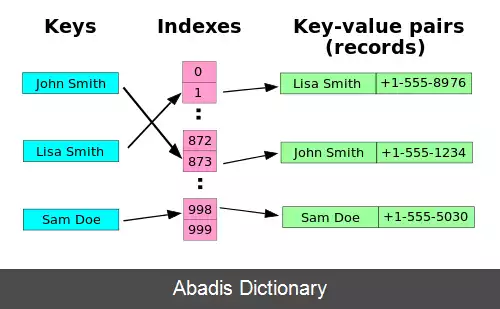
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفیک تابع هش ایدئال باید هر کلید ممکن را به یک خانه از آرایه متناظر کند، اما این امر در عمل به ندرت اتفاق می افتد. در بیشتر توابع هش فرض بر این است که به طور طبیعی تصادم رخ می دهد، یعنی دو کلید متفاوت، مقدار هش یکسان پیدا می کنند و در نتیجه وارد یک خانه از آرایه می شوند.
در یک جدول با ابعاد خوب، متوسط هزینه ( تعداد دستورالعمل ها ) برای هر جستجو به تعداد عناصر نگهداری شده در آرایه بستگی ندارد. جداول هش بسیاری طراحی شده که مرتبه زمانی حذف و افزودن یک جفت کلید و مقدار اختیاری به طور متوسط ثابت است.
در بسیاری از اوقات، جداول درهم سازی بسیار کارآمدتر از درخت های جستجو یا هر داده ساختار جستجوی دیگری عمل می کند. به همین دلیل، جداول هش به طور گسترده درنرم افزارها، به خصوص در آرایه های شرکت پذیر، ساختار فهرست پایگاه داده، حافظه های نهان و مجموعه ها کاربرد دارند.
جداول هش نباید با هش لیست ها و درخت های هش که در رمزنگاری و انتقال داده استفاده می شود اشتباه گرفته شوند.
در قلب یک جدول درهم سازی، یک آرایهٔ ساده از عناصر وجود دارد؛ که معمولاً به سادگی جدول هش نامیده می شود. جدول هش اندیس یک کلید را محاسبه می کند و از آن اندیس برای جای دادن آن کلید در جدول استفاده می کند.
الگوریتم پایه و اصلی برای جستجو ساده است:
index = f ( key, array_length ) که در آن:
• f: تابع درهم سازی است که اندیس را بر اساس آرایه برمی گرداند
• index: یک اندیس از آرایه است
• key: کلیدی است که قرار است وارد آرایه شود
• array_length: طول آرایه است
فرض کنیم می خواهیم ساختمان داده ای بسازیم و در آن نام ده هزار نفر را ذخیره کنیم. راه حل خام و ساده برای این مسئله آن است که آرایه ای از رشته ها به طول ده هزار بسازیم و نام ها را در آن بریزیم. حال فرض کنیم نامی به ما داده شده است و ما می خواهیم بدانیم این نام در میان داده های ما وجود دارد یا خیر. برای این کار مجبوریم همه داده های درون آرایه از یک تا ده هزار را بپیماییم تا ببینیم نام مورد نظر وجود دارد یا نه. در حقیقت عملیات جستجو در ساختمان داده ما دارای مرتبه زمانی n خواهد بود. ( n تعداد داده ها است )


wiki: جدول درهمک سازی