
توزیع دیریکله در نظریه احتمال و آمار یک توزیع پیوسته است. این توزیع به طور کلی حالت گسترش یافته توزیع بتا برای توابع چندمتغیره است. معمولاً از توزیع دیریکله به عنوان توزیع پیشین در مدل سازی بیزی استفاده می شود؛ چرا که توزیع دیریکله مزدوج پیشین ( conjugate prior ) برای توزیع چندجمله ای و توزیع دسته ای ( categorical ) است. تعمیم این توزیع فرایند دیریکله است.
تابع چگالی احتمال آن به صورت زیر است:
به ازای همهٔ x1, . . . , xK–1> 0 بطوریکه x1 + . . . + xK–1 < 1, و xK = 1 – x1 – . . . – xK–1. چگالی در خارج از این ناحیه صفر است. ثابت نرمالیزاسیون به صورت زیر تعریف می شود:
یک حالت خاص زمانی است که تمامی مقادیر α مقدار یکسانی داشته باشند، که در اینصورت آن را توزیع دیریکلهٔ متقارن می نامیم. در این حالت توزیع ساده می شود به:
زمانی که α = 1 توزیع معادل با توزیع یکنواخت روی یک تکیه گاه ( ریاضی ) سیمپلکس K − 1 بعدی.
فرض کنیم متغیرهای تصادفی X = ( X 1 , … , X K ) ∼ Dir ( α ) و : X K = 1 − X 1 − ⋯ − X K − 1 . را در اختیار داریم. تعریف می کنیم α 0 = ∑ i = 1 K α i . بنابرین [ ۱] [ ۲]
علاوه بر این اگر if i ≠ j
مد توزیع برداری مانند ( x1, . . . , xK ) است که در آن:
توزیع های حاشیه ای توزیع دیریکله، توزیع بتا هستند.
این به این معنی است که اگر در مدلسازی مجموعه ای از داده ها از توزیع چندجمله ای/دسته ای استفاده کنیم و توزیع پیشین را دیریکله قرار دهیم، توزیع پسین الزاماً یک توزیع دیریکله خواهد بود. به زبان ریاضی یعنی
بنابرین روابط مقابل برقرار هستند:
می دانیم
و Cov = ψ ′ ( α i ) δ i j − ψ ′ ( α 0 ) که در آن ψ تابع تابع دایگاما و ψ ′ تابع ترایگاما، δ i j دلتای کرونکر است.
اگر X = ( X 1 , … , X K ) ∼ Dir ( α 1 , … , α K ) اگر متغیرهای تصادفی i - ام و j - م را با هم ادغام کنیم دیریکلهٔ حاصل برابر است با: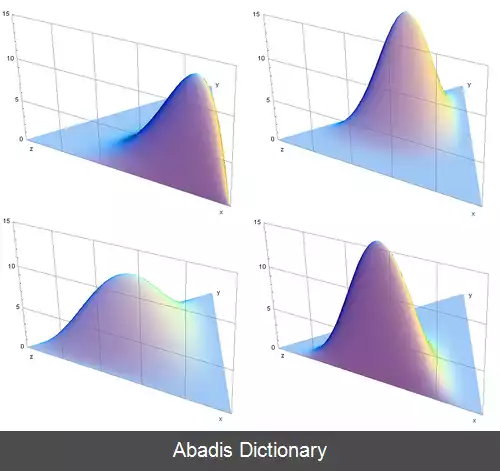
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفتابع چگالی احتمال آن به صورت زیر است:
به ازای همهٔ x1, . . . , xK–1> 0 بطوریکه x1 + . . . + xK–1 < 1, و xK = 1 – x1 – . . . – xK–1. چگالی در خارج از این ناحیه صفر است. ثابت نرمالیزاسیون به صورت زیر تعریف می شود:
یک حالت خاص زمانی است که تمامی مقادیر α مقدار یکسانی داشته باشند، که در اینصورت آن را توزیع دیریکلهٔ متقارن می نامیم. در این حالت توزیع ساده می شود به:
زمانی که α = 1 توزیع معادل با توزیع یکنواخت روی یک تکیه گاه ( ریاضی ) سیمپلکس K − 1 بعدی.
فرض کنیم متغیرهای تصادفی X = ( X 1 , … , X K ) ∼ Dir ( α ) و : X K = 1 − X 1 − ⋯ − X K − 1 . را در اختیار داریم. تعریف می کنیم α 0 = ∑ i = 1 K α i . بنابرین [ ۱] [ ۲]
علاوه بر این اگر if i ≠ j
مد توزیع برداری مانند ( x1, . . . , xK ) است که در آن:
توزیع های حاشیه ای توزیع دیریکله، توزیع بتا هستند.
این به این معنی است که اگر در مدلسازی مجموعه ای از داده ها از توزیع چندجمله ای/دسته ای استفاده کنیم و توزیع پیشین را دیریکله قرار دهیم، توزیع پسین الزاماً یک توزیع دیریکله خواهد بود. به زبان ریاضی یعنی
بنابرین روابط مقابل برقرار هستند:
می دانیم
و Cov = ψ ′ ( α i ) δ i j − ψ ′ ( α 0 ) که در آن ψ تابع تابع دایگاما و ψ ′ تابع ترایگاما، δ i j دلتای کرونکر است.
اگر X = ( X 1 , … , X K ) ∼ Dir ( α 1 , … , α K ) اگر متغیرهای تصادفی i - ام و j - م را با هم ادغام کنیم دیریکلهٔ حاصل برابر است با:

wiki: توزیع دیریکله