
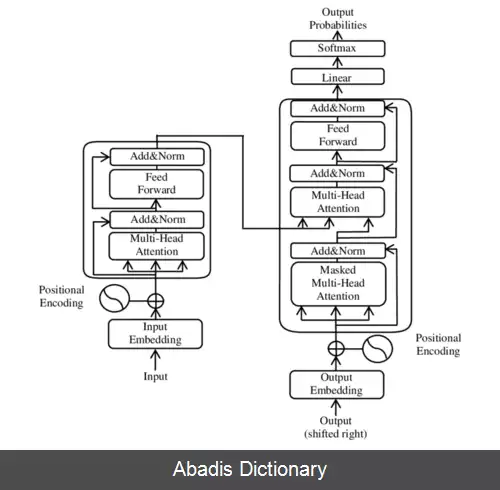
ترنسفورمرها (یادگیری ماشین). ترانسفورمر یک مدل یادگیری عمیق است که مکانیسم توجه به خود، به طور متفاوتی اهمیت هر بخش از داده های ورودی را وزن می کند. عمدتاً در زمینه های پردازش زبان طبیعی ( NLP ) و بینایی رایانه ای ( CV ) استفاده می شود. [ ۱]
مانند شبکه عصبی بازگشتی ( RNN ) ، ترانسفورمرها برای مدیریت داده های ورودی متوالی، مانند زبان طبیعی، برای کارهایی مانند ترجمه و خلاصه متن طراحی شده اند. با این حال، برخلاف شبکه عصبی بازگشتیها، ترانسفورمرها لزوماً داده ها را به ترتیب پردازش نمی کنند. در عوض، مکانیسم توجه زمینه را برای هر موقعیتی در دنباله ورودی فراهم می کند. به عنوان مثال، اگر داده ورودی یک جمله زبان طبیعی باشد، ترانسفورمر نیازی به پردازش ابتدای جمله قبل از پایان ندارد. در عوض، زمینه ای را مشخص می کند که به هر کلمه در جمله معنا می بخشد. این ویژگی اجازه می دهد تا موازی سازی بیشتر از شبکه عصبی بازگشتیها باشد و بنابراین زمان آموزش را کاهش می دهد. [ ۱]
ترانسفورمرها در سال ۲۰۱۷ توسط تیمی در Google Brain[ ۱] معرفی شدند و به طور فزاینده ای مدل انتخابی برای مشکلات NLP هستند، [ ۱] جایگزین مدل های شبکه عصبی بازگشتی مانند حافظه کوتاه - مدت طولانی ( LSTM ) . موازی سازی آموزش اضافی امکان آموزش بر روی مجموعه داده های بزرگتر از زمانی که ممکن بود را می دهد. این منجر به توسعه سیستم های از پیش آموزش دیده مانند برت ( مدل زبانی ) ( نمایش رمزگذار دوطرفه از ترانسفورمرها ) و GPT ( تبدیل پیش آموزش شده تولیدی ) ، که با مجموعه داده های زبانی بزرگ، مانند ویکی پدیا و Common Crawl آموزش دیده اند، و می توان آنها را برای کارهای خاص به خوبی تنظیم کرد. [ ۲]
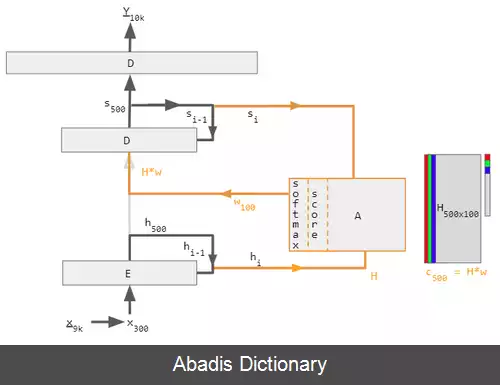
قبل از ترانسفورمرها، بیشتر سیستم های NLP پیشرفته به شبکه عصبی بازگشتیهای دروازه دار مانند حافظه طولانی کوتاه - مدت و واحد بازگشتی دروازه ای ( GRU ) با مکانیسم توجه اضافه شده بود. ترانسفورمرها بر اساس این فناوری های توجه بدون استفاده از ساختار شبکه عصبی بازگشتی ساخته شده اند، و این واقعیت را برجسته می کند که مکانیسم های توجه به تنهایی می توانند عملکرد شبکه عصبی بازگشتیها را با توجه مطابقت دهند.
شبکه عصبی بازگشتیهای دروازه ای توکن ها را به صورت متوالی پردازش می کنند و یک بردار حالت را حفظ می کنند که حاوی نمایشی از داده هایی است که بعد از هر نشانه مشاهده می شود. برای پردازش علامت n ام، مدل حالتی را که جمله را تا توکن n − 1 نشان می دهد با اطلاعات نشانه جدید برای ایجاد یک حالت جدید، نشان دهنده جمله تا نشانه n . از نظر تئوری، اطلاعات یک توکن می تواند به طور دلخواه در طول توالی منتشر شود، اگر در هر نقطه، وضعیت به رمزگذاری اطلاعات متنی در مورد نشانه ادامه دهد. در عمل، این مکانیسم ناقص است: مسئله گرادیان ناپدید شدن وضعیت مدل را در پایان یک جمله طولانی بدون اطلاعات دقیق و قابل استخراج دربارهٔ نشانه های قبلی ترک می کند. وابستگی محاسبات توکن به نتایج محاسبات توکن های قبلی نیز موازی کردن محاسبات روی سخت افزار یادگیری عمیق مدرن را دشوار می کند. این می تواند آموزش شبکه عصبی بازگشتیها را ناکارآمد کند.
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفمانند شبکه عصبی بازگشتی ( RNN ) ، ترانسفورمرها برای مدیریت داده های ورودی متوالی، مانند زبان طبیعی، برای کارهایی مانند ترجمه و خلاصه متن طراحی شده اند. با این حال، برخلاف شبکه عصبی بازگشتیها، ترانسفورمرها لزوماً داده ها را به ترتیب پردازش نمی کنند. در عوض، مکانیسم توجه زمینه را برای هر موقعیتی در دنباله ورودی فراهم می کند. به عنوان مثال، اگر داده ورودی یک جمله زبان طبیعی باشد، ترانسفورمر نیازی به پردازش ابتدای جمله قبل از پایان ندارد. در عوض، زمینه ای را مشخص می کند که به هر کلمه در جمله معنا می بخشد. این ویژگی اجازه می دهد تا موازی سازی بیشتر از شبکه عصبی بازگشتیها باشد و بنابراین زمان آموزش را کاهش می دهد. [ ۱]
ترانسفورمرها در سال ۲۰۱۷ توسط تیمی در Google Brain[ ۱] معرفی شدند و به طور فزاینده ای مدل انتخابی برای مشکلات NLP هستند، [ ۱] جایگزین مدل های شبکه عصبی بازگشتی مانند حافظه کوتاه - مدت طولانی ( LSTM ) . موازی سازی آموزش اضافی امکان آموزش بر روی مجموعه داده های بزرگتر از زمانی که ممکن بود را می دهد. این منجر به توسعه سیستم های از پیش آموزش دیده مانند برت ( مدل زبانی ) ( نمایش رمزگذار دوطرفه از ترانسفورمرها ) و GPT ( تبدیل پیش آموزش شده تولیدی ) ، که با مجموعه داده های زبانی بزرگ، مانند ویکی پدیا و Common Crawl آموزش دیده اند، و می توان آنها را برای کارهای خاص به خوبی تنظیم کرد. [ ۲]
قبل از ترانسفورمرها، بیشتر سیستم های NLP پیشرفته به شبکه عصبی بازگشتیهای دروازه دار مانند حافظه طولانی کوتاه - مدت و واحد بازگشتی دروازه ای ( GRU ) با مکانیسم توجه اضافه شده بود. ترانسفورمرها بر اساس این فناوری های توجه بدون استفاده از ساختار شبکه عصبی بازگشتی ساخته شده اند، و این واقعیت را برجسته می کند که مکانیسم های توجه به تنهایی می توانند عملکرد شبکه عصبی بازگشتیها را با توجه مطابقت دهند.
شبکه عصبی بازگشتیهای دروازه ای توکن ها را به صورت متوالی پردازش می کنند و یک بردار حالت را حفظ می کنند که حاوی نمایشی از داده هایی است که بعد از هر نشانه مشاهده می شود. برای پردازش علامت n ام، مدل حالتی را که جمله را تا توکن n − 1 نشان می دهد با اطلاعات نشانه جدید برای ایجاد یک حالت جدید، نشان دهنده جمله تا نشانه n . از نظر تئوری، اطلاعات یک توکن می تواند به طور دلخواه در طول توالی منتشر شود، اگر در هر نقطه، وضعیت به رمزگذاری اطلاعات متنی در مورد نشانه ادامه دهد. در عمل، این مکانیسم ناقص است: مسئله گرادیان ناپدید شدن وضعیت مدل را در پایان یک جمله طولانی بدون اطلاعات دقیق و قابل استخراج دربارهٔ نشانه های قبلی ترک می کند. وابستگی محاسبات توکن به نتایج محاسبات توکن های قبلی نیز موازی کردن محاسبات روی سخت افزار یادگیری عمیق مدرن را دشوار می کند. این می تواند آموزش شبکه عصبی بازگشتیها را ناکارآمد کند.


