
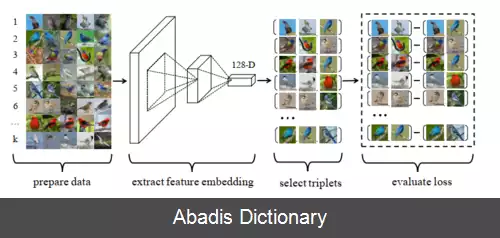
در روش های یادگیری مبتنی بر شباهت، هدف یاد گرفتن یک تابع شباهت یا معیار فاصله است که مقدار آن، نوسان کمی بین اعضای یک کلاس و نوسان زیادی در خارج از آن کلاس داشته باشد. تابع هزینه تریپلت ( انگلیسی: Triplet loss ) ، نیز یکی از توابع هزینه محبوب در این نوع یادگیری ها محسوب می شود و موفقیت زیادی در بسیاری از وظایف بینایی رایانه ای مانند بازیابی تصویر، تشخیص هویت افراد، تشخیص چهره و غیره داشته است. این تابع هزینه به دلیل عملکرد خوب در مسائلی که با تعداد برچسب بالا و تعداد کم نمونه های آموزشی هر کلاس روبرو هستیم، محبوب شده است. در روش های مرسوم طبقه بندی، تعداد پارامترها به صورت خطی همراه با تعداد برچسب ها افزایش پیدا می کند و آموزش یک تابع سافت مکس برای میلیون ها برچسب کاری انجام نشدنی است. یک شبکه عصبی که در آن از تابع هزینه تریپلت، استفاده شده باشد، می تواند با یادگیری یک بردار ویژگی فشرده عملکرد بسیار خوبی در مسائل چند کلاسه همچون بازیابی تصویر داشته باشد. به شبکه عصبی که در آن از تابع هزینه تریپلت استفاده شده باشد، شبکه تریپلت ( انگلیسی: Triplet Net ) گفته می شود.
این تابع هزینه اولین بار سال ۲۰۰۹ توسط Weinberger و Saul معرفی شد. آن ها این معیار را به گونه ای آموزش دادند که k نزدیکترین داده های در همسایگی هم، همگی متعلق به یک کلاس باشند و در حداقل فاصله از هم قرار بگیرند و داده های کلاس های متفاوت در حداکثر فاصله از آن ها قرار بگیرند. این تابع هزینه، مستقیماً یک شبکه عصبی پیچشی عمیق را بهینه سازی می کند و بردارهای ویژگی را به گونه ای تولید می کند که تصاویر مشابه با یک تصویر نمونه ( انگلیسی: Anchor sample ) ، در فاصله کمی از آن قرار بگیرد. تصاویر مشابه را نمونه های مثبت ( انگلیسی: positive samples ) و تصاویر متفاوت را نمونه های منفی ( انگلیسی: negative samples ) می نامند. برای مثال در یک مسئله تشخیص چهره، هویت هر فرد موجود در مجموعه آموزشی، به عنوان یک کلاس در نظر گرفته می شود و شبکه برای طبقه بندی و تشخیص صحیح تصاویر هر کلاس آموزش می بیند. شبکه آموزش دیده، به عنوان یک استخراج کننده ویژگی استفاده می شود. در نهایت، از یک معیار خاص، مانند فاصله بین بردارها، برای رده بندی ویژگی های استخراج شده انتخاب می شود.
در مسائل طبقه بندی سنتی، مدل با مجموعه ای از مثال ها آموزش می دید تا بتواند با دریافت یک داده جدید در ورودی، خروجی صحیح را برای هر کلاس محاسبه کند. برای مثال اگر از یک شبکه عصبی برای طبقه بندی یک مسئله با سه کلاس سگ و گربه و اسب استفاده کنید، در صورت آموزش صحیح شبکه، با دادن تصویر یک سگ به آن، مقدار احتمال مربوط به کلاس سگ ( کلاس صحیح ) می بایست بیشترین مقدار را داشته باشد.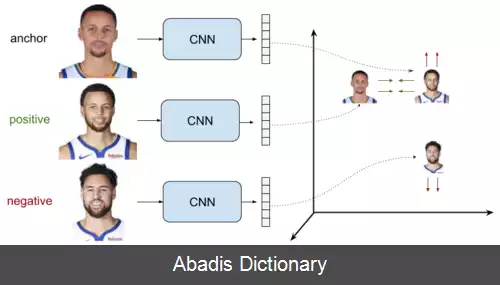
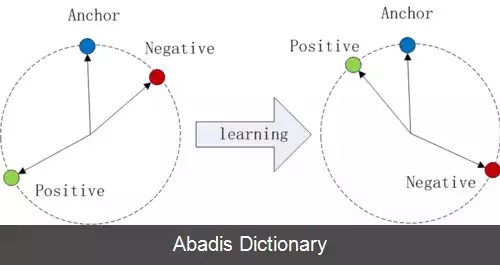
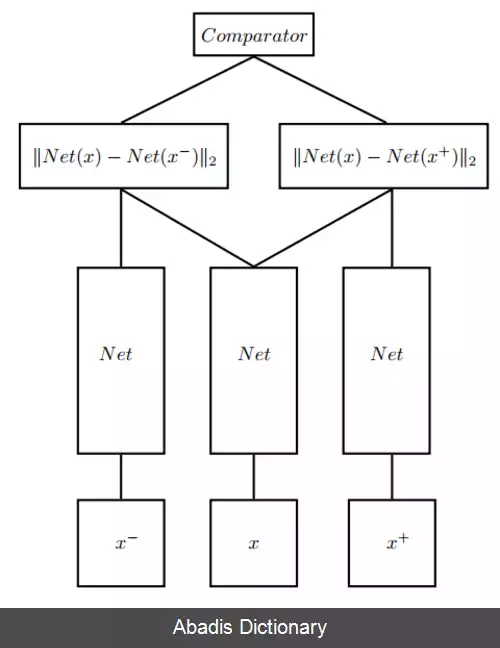
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفاین تابع هزینه اولین بار سال ۲۰۰۹ توسط Weinberger و Saul معرفی شد. آن ها این معیار را به گونه ای آموزش دادند که k نزدیکترین داده های در همسایگی هم، همگی متعلق به یک کلاس باشند و در حداقل فاصله از هم قرار بگیرند و داده های کلاس های متفاوت در حداکثر فاصله از آن ها قرار بگیرند. این تابع هزینه، مستقیماً یک شبکه عصبی پیچشی عمیق را بهینه سازی می کند و بردارهای ویژگی را به گونه ای تولید می کند که تصاویر مشابه با یک تصویر نمونه ( انگلیسی: Anchor sample ) ، در فاصله کمی از آن قرار بگیرد. تصاویر مشابه را نمونه های مثبت ( انگلیسی: positive samples ) و تصاویر متفاوت را نمونه های منفی ( انگلیسی: negative samples ) می نامند. برای مثال در یک مسئله تشخیص چهره، هویت هر فرد موجود در مجموعه آموزشی، به عنوان یک کلاس در نظر گرفته می شود و شبکه برای طبقه بندی و تشخیص صحیح تصاویر هر کلاس آموزش می بیند. شبکه آموزش دیده، به عنوان یک استخراج کننده ویژگی استفاده می شود. در نهایت، از یک معیار خاص، مانند فاصله بین بردارها، برای رده بندی ویژگی های استخراج شده انتخاب می شود.
در مسائل طبقه بندی سنتی، مدل با مجموعه ای از مثال ها آموزش می دید تا بتواند با دریافت یک داده جدید در ورودی، خروجی صحیح را برای هر کلاس محاسبه کند. برای مثال اگر از یک شبکه عصبی برای طبقه بندی یک مسئله با سه کلاس سگ و گربه و اسب استفاده کنید، در صورت آموزش صحیح شبکه، با دادن تصویر یک سگ به آن، مقدار احتمال مربوط به کلاس سگ ( کلاس صحیح ) می بایست بیشترین مقدار را داشته باشد.





wiki: تابع هزینه تریپلت