
آنالیز پنهان مفهومی. آنالیز مفاهیم نهفته یک روش در پردازش زبان طبیعی است که در مدلسازی ارتباط مفهومی بین تعدادی متن بر اساس مجموعهٔ کلماتی که دربردارند کاربرد دارد. [ ۱]
آنالیز مفاهیم نهفته با فرض این که کلمات با بار معنایی مشابه در بخش های یکسانی از نوشته قرار می گیرند، کار خود را انجام می هد ( طبق Distributional semantics ) .
یک ماتریس که ردیف های آن کلمات و ستون های آن نوشته ها را نشان می دهند، بیانگر تعداد هر واژه در هر نوشته خواهد بود. این ماتریس معمولا با متن های زیادی ایجاد می شود. در نتیجه برای کاهش تعداد ردیف ها از تکنیک تجزیه مقدارهای منفرد استفاده می شود که در عین کاهش تعداد ردیف ها ساختار مشابهت بین ستون ها را حفظ می کند. در نهایت نوشته ها با محاسبه «تشابه کسینوسی» بین هر دو ستون مقایسه می شوند.
آنالیز مفاهیم نهفته از یک ماتریس استفاده می کند که بیانگر میزان نمایان شدن هر کلمه در هر نوشته است. این ماتریس یک ماتریس تنک است که معمولا سطر های آن بیانگر کلمات و ستون های بیانگر نوشته ها هستند. یک روش معمول برای مقدار هر درایه در این ماتریس روش فراوانی وزنی تی اف - آی دی اف است. این روش درواقع میزان اهمیت یک کلمه را در یک نوشته نشان می دهد. عبارات نادر برای نشان دادن اهمیتشان وزن بیشتری دارند.
بعد از تشکیل ماتریس وقوع ، نیاز است که آن را با یک تقریب کم رتبه از آن جایگزین کنیم. از جمله دلایل این عمل می توان به موارد زیر اشاره کرد:
• ماتریس وقوع اصلی بسیار برای محاسبات بزرگ است.
• ماتریس وقوع اصلی ممکن است حاوی نویز باشد. ( برای مثال بعضی از حالت های یک کلمه ممکن است نیاز به حذف شدن داشته باشند. )
• ماتریس وقوع اصلی تنک است. همچنین ما ممکن است علاقمند به این باشیم که کلمات مرتبط با هر نوشته را بررسی کنیم.
روند کاهش رتبه به این شکل است که بعضی از ابعاد با هم ترکیب می شوند. در این حالت کلمات هم معنی را کنار هم قرار می دهد. و همچنین مشکل چند معنایی کلمات را نیز تا حدودی حل می کند.
فضای کم بعد ایجاد شده می تواند در موارد زیر استفاده شود:
• مقایسه نوشته ها در فضای کم بعد ( خوشه بندی داده، طبقه بندی نوشته ها )
• یافتن نوشته های مشابه در بین زبان های مختلف پس از آنالیز یک سری نوشته ترجمه شده ( CLIR )
• یافتن ارتباط بین عبارات ( هم معنایی و چند معنایی )
• یافتن نوشته های مرتبط بر حسب عبارت داده شده ( کاوش اطلاعات )
• یافتن بهترین شباهت بین گروه های کوچک از عبارات ( برای مثال سوالات چند گزینه ای ) [ ۲]
• گسترش فضای خصوصیات در یادگیری ماشین یا سیستم های استخراج متن[ ۳]
• آنالیز وابستگی کلمات در چهارچوب متن[ ۴]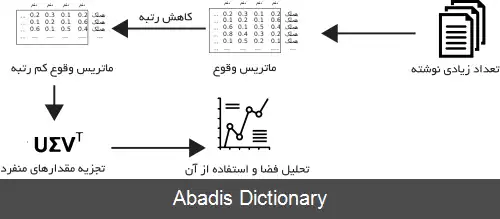
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفآنالیز مفاهیم نهفته با فرض این که کلمات با بار معنایی مشابه در بخش های یکسانی از نوشته قرار می گیرند، کار خود را انجام می هد ( طبق Distributional semantics ) .
یک ماتریس که ردیف های آن کلمات و ستون های آن نوشته ها را نشان می دهند، بیانگر تعداد هر واژه در هر نوشته خواهد بود. این ماتریس معمولا با متن های زیادی ایجاد می شود. در نتیجه برای کاهش تعداد ردیف ها از تکنیک تجزیه مقدارهای منفرد استفاده می شود که در عین کاهش تعداد ردیف ها ساختار مشابهت بین ستون ها را حفظ می کند. در نهایت نوشته ها با محاسبه «تشابه کسینوسی» بین هر دو ستون مقایسه می شوند.
آنالیز مفاهیم نهفته از یک ماتریس استفاده می کند که بیانگر میزان نمایان شدن هر کلمه در هر نوشته است. این ماتریس یک ماتریس تنک است که معمولا سطر های آن بیانگر کلمات و ستون های بیانگر نوشته ها هستند. یک روش معمول برای مقدار هر درایه در این ماتریس روش فراوانی وزنی تی اف - آی دی اف است. این روش درواقع میزان اهمیت یک کلمه را در یک نوشته نشان می دهد. عبارات نادر برای نشان دادن اهمیتشان وزن بیشتری دارند.
بعد از تشکیل ماتریس وقوع ، نیاز است که آن را با یک تقریب کم رتبه از آن جایگزین کنیم. از جمله دلایل این عمل می توان به موارد زیر اشاره کرد:
• ماتریس وقوع اصلی بسیار برای محاسبات بزرگ است.
• ماتریس وقوع اصلی ممکن است حاوی نویز باشد. ( برای مثال بعضی از حالت های یک کلمه ممکن است نیاز به حذف شدن داشته باشند. )
• ماتریس وقوع اصلی تنک است. همچنین ما ممکن است علاقمند به این باشیم که کلمات مرتبط با هر نوشته را بررسی کنیم.
روند کاهش رتبه به این شکل است که بعضی از ابعاد با هم ترکیب می شوند. در این حالت کلمات هم معنی را کنار هم قرار می دهد. و همچنین مشکل چند معنایی کلمات را نیز تا حدودی حل می کند.
فضای کم بعد ایجاد شده می تواند در موارد زیر استفاده شود:
• مقایسه نوشته ها در فضای کم بعد ( خوشه بندی داده، طبقه بندی نوشته ها )
• یافتن نوشته های مشابه در بین زبان های مختلف پس از آنالیز یک سری نوشته ترجمه شده ( CLIR )
• یافتن ارتباط بین عبارات ( هم معنایی و چند معنایی )
• یافتن نوشته های مرتبط بر حسب عبارت داده شده ( کاوش اطلاعات )
• یافتن بهترین شباهت بین گروه های کوچک از عبارات ( برای مثال سوالات چند گزینه ای ) [ ۲]
• گسترش فضای خصوصیات در یادگیری ماشین یا سیستم های استخراج متن[ ۳]
• آنالیز وابستگی کلمات در چهارچوب متن[ ۴]

wiki: آنالیز پنهان مفهومی