
الگوریتم های تطابق رشته ای، که گاهی الگوریتم های جسیتجوی رشته ای گقته می شوند، دستهٔ مهمی از الگوریتم های رشته ای هستند که سعی می کنند محل رخداد یک یا چند رشته ( الگو ) در یک رشتهٔ بزرگتر ( یا متن ) را پیدا کنند.
Σ را مجموعهٔ الفبای محدودی فرض کنید. معمولا، هم الگو و هم متن مورد نظر، ترکیبی از عناصرΣ می باشند. Σ می تواند یک الفبای انسانی معمولی باشد ( مثلا، حروف A تا Z در زبان انگلیسی ) . در کاربردهای دیگر ممکن است از الفبای دودویی ( { ( Σ = {0, 1 ) یا الفبای DNA در بیوانفورماتیک استفاده شود.
به طور خاص، این که رشته چگونه رمز شده است می تواند روی الگوریتم ملموس تطابق، تأثیرگذار باشد. مخصوصاً اگر رمز نگاری طولی متغیر مورد استفاده قرار گیرد، به کندی می توان کاراکتر N ام را پیدا کرد. این می تواند به طور محسوسی الگوریتم های جستجوی پیشرفته تر را کند، کند. یک راه حل این است که به دنبال دنباله ای از واحدهای رمز بگردیم، اما این روش ممکن است باعث ایجاد مطابقت های اشتباه گردد. اگر رمز نگاری به گونه ای خاص طراحی شده باشد، از این مشکل جلوگیری می شود.
الگوریتم های مختلف را می توان بر اساس تعداد الگوهایی که استفاده می کنند دسته بندی کرد.
• الگوریتم جستجوی رشتهٔ نیو
• الگوریتم جستجوی رشتهٔ رابین - کارپ
• جستجو بر پایهٔ ماشین های خودکار محدود حالته
• الگوریتم جستحوی رشته ای Boyer - MooreKnuth - Morris - Pratt
• لگوریتمBitap
• الگوریتم Aho - Corasick
• الگوریتمCommentz - Walter
• الگوریتم جستجوی رشتهٔ رابین - کارپ
طبیعتا در این حالت تعداد الگوها غیرقابل شمارش است. آن ها را معمولاً با یک عبارت عادی نمایش می دهند.
تقسیم بندی های دیگری نیز امکان پذیر است. یکی از رایج ترین آن ها پیش پردازش را به عنوان معیار در نظر می گیرد.
آسان ترین و ناکارامدترین راه برای آنکه ببینیم کجا یک رشته در رشته ای دیگر تکرار شده، آن است که تمام مکان های ممکن را یکی یکی بررسی کنیم.
در حالت نورمال، برای هر مکان اشتباه، فقط کافی است یک یا دو کاراکتر را چک کنیم پس در حالت متوسط، این O ( n + m ) مرحله طول می کشد، که n طول متن وm اندازهٔ کلمهٔ مورد جستجو ( کلید ) است; اما در بدترین حالت، جستجوی یک رشته مثل "aaaab" در یک رشته مثل "aaaaaaaaab", O ( nm ) مرحله طول می کشد.
در این روش، با ساختن یکماشین محدود قطعی ( deterministic ) که رشته هایی را که حاوی رشتهٔ مطلوب مورد جستجو هستند، تشخیص می دهد. ساخت آن ها هزینه بر است اما بسیار سربع هستند. مثلاً DFA که در سمت راست نشان داده شده است کلمهٔ "MOMMY" را تشخیص می دهد. این شیوه در عمل برای جستجوی عبارات معمولی دلخواه، عمومیت داده می شود.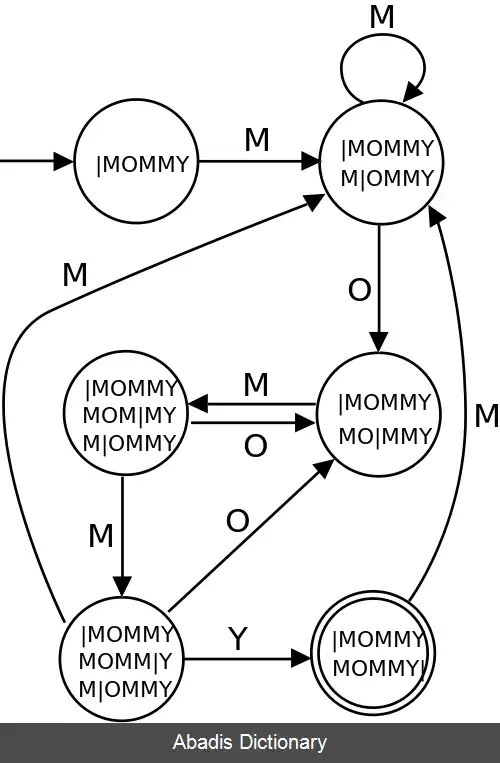
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفΣ را مجموعهٔ الفبای محدودی فرض کنید. معمولا، هم الگو و هم متن مورد نظر، ترکیبی از عناصرΣ می باشند. Σ می تواند یک الفبای انسانی معمولی باشد ( مثلا، حروف A تا Z در زبان انگلیسی ) . در کاربردهای دیگر ممکن است از الفبای دودویی ( { ( Σ = {0, 1 ) یا الفبای DNA در بیوانفورماتیک استفاده شود.
به طور خاص، این که رشته چگونه رمز شده است می تواند روی الگوریتم ملموس تطابق، تأثیرگذار باشد. مخصوصاً اگر رمز نگاری طولی متغیر مورد استفاده قرار گیرد، به کندی می توان کاراکتر N ام را پیدا کرد. این می تواند به طور محسوسی الگوریتم های جستجوی پیشرفته تر را کند، کند. یک راه حل این است که به دنبال دنباله ای از واحدهای رمز بگردیم، اما این روش ممکن است باعث ایجاد مطابقت های اشتباه گردد. اگر رمز نگاری به گونه ای خاص طراحی شده باشد، از این مشکل جلوگیری می شود.
الگوریتم های مختلف را می توان بر اساس تعداد الگوهایی که استفاده می کنند دسته بندی کرد.
• الگوریتم جستجوی رشتهٔ نیو
• الگوریتم جستجوی رشتهٔ رابین - کارپ
• جستجو بر پایهٔ ماشین های خودکار محدود حالته
• الگوریتم جستحوی رشته ای Boyer - MooreKnuth - Morris - Pratt
• لگوریتمBitap
• الگوریتم Aho - Corasick
• الگوریتمCommentz - Walter
• الگوریتم جستجوی رشتهٔ رابین - کارپ
طبیعتا در این حالت تعداد الگوها غیرقابل شمارش است. آن ها را معمولاً با یک عبارت عادی نمایش می دهند.
تقسیم بندی های دیگری نیز امکان پذیر است. یکی از رایج ترین آن ها پیش پردازش را به عنوان معیار در نظر می گیرد.
آسان ترین و ناکارامدترین راه برای آنکه ببینیم کجا یک رشته در رشته ای دیگر تکرار شده، آن است که تمام مکان های ممکن را یکی یکی بررسی کنیم.
در حالت نورمال، برای هر مکان اشتباه، فقط کافی است یک یا دو کاراکتر را چک کنیم پس در حالت متوسط، این O ( n + m ) مرحله طول می کشد، که n طول متن وm اندازهٔ کلمهٔ مورد جستجو ( کلید ) است; اما در بدترین حالت، جستجوی یک رشته مثل "aaaab" در یک رشته مثل "aaaaaaaaab", O ( nm ) مرحله طول می کشد.
در این روش، با ساختن یکماشین محدود قطعی ( deterministic ) که رشته هایی را که حاوی رشتهٔ مطلوب مورد جستجو هستند، تشخیص می دهد. ساخت آن ها هزینه بر است اما بسیار سربع هستند. مثلاً DFA که در سمت راست نشان داده شده است کلمهٔ "MOMMY" را تشخیص می دهد. این شیوه در عمل برای جستجوی عبارات معمولی دلخواه، عمومیت داده می شود.

wiki: الگوریتم تطابق رشته ها